



Science has a problem. There is an element of unavoidable randomness in research. Combine that with a propensity to disproportionately publish notable research, and you end up with two factors that distort our picture of the evidence. First, results that are not sufficiently “interesting” may remain unpublished and unknown. Second, in anticipation of this, researchers might bend their research methods to force their results to be “interesting” and hence, publishable (this practice is sometimes called p-hacking). The resulting biased presentation of evidence presents a challenge for science’s cumulative project to better understand how our world works.
On the other hand, it isn’t necessarily a bad thing that top journal seek to highlight research that challenges our existing beliefs about the world. Even if there aren’t publishing space constraints in a digital world, attention is limited. It makes sense for top journals to curate the research that is most useful to an audience with limited time. That could mean privileging research that provides evidence for some specific theory of how the world works, rather than null results that maybe don’t (Frankel and Kasy 2021 develops this idea more fully).
But not all journals need to fill that role. We could create a different set of publication outlets whose primary purpose is to provide peer review, archiving, and search engine optimization services and not to curate research for casual readers. These outlets could be a home to results not publishable in top journals. In fact, some journals like this already exist, such as the Series on Unsurprising Results in Economics (acronym: SURE). That would enable the full set of results related to a particular topic to be discoverable, with a little bit of effort. We might end up with poorly informed casual readers, who only read top journals, but inventors, policy-makers, and researchers who need to get an accurate idea of the actual state of the evidence would know to dig deeper to get the whole story.
Would that work? One place to get some evidence on this is to look at our experience with preprint servers.
Preprint Servers as a Secondary Publication Outlet?
Preprint servers are places where researchers - typically with some kind of affiliation - can post work that is nominally in progress but usually quite close to a finished product. They are not subject to peer review or editorial discretion, and so could, in principle, serve as a home for research results that don’t end up getting published, perhaps because of publication bias.
Indeed, a non-negligible share of work on preprints is never published. Baumann and Wohlrabe (2020) estimate that about 25% of working papers published on major preprint servers in economics are never published. Lariviere et al. (2014) estimate 36% of working papers on arXiv are never published in a journal listed on the Web of Science, and Tsunoda et al. (2020) estimate 59% of papers posted on bioRxiv during 2013-2019 were not (yet) published.
We have some evidence these preprint servers do help mitigate censoring. Fanelli, Costas, and Ioannidis (2017) obtain 1,910 meta-analyses drawn from all areas of science, and pull from these 33,355 datapoints from original studies. They then look at the size of estimated effects in each of these disciplines for those published in peer-reviewed journals and those published elsewhere (i.e., on preprint servers, but also in conference papers, personal communications, unpublished drafts, graduate theses, etc.). The latter group - which hasn’t been through explicit peer review - is often called “gray literature.” Fanelli, Costas, and Ioannidis find gray literature articles do report smaller effect sizes than those in peer-reviewed journals. That’s consistent with papers on preprint servers facing less publication bias or pressure to engage in p-hacking.
But the effect is pretty small, explaining on the order of 1% of the variation in outcomes. That’s not too surprising, in light of a finding from Franco, Malhotra, and Simonovits (2014) I have discussed elsewhere - in their study of the social sciences, most null results were never written up at all, much less posted publicly on a preprint server. This seemed to be because the researchers believed these studies faced a hopeless path to publication, and hence weren’t worth the effort of writing up.
In fact, restricting attention to the null results that did get written up, they were published at about the same rate as positive results. One interpretation of that is sometimes null results are, in fact, interesting, and so they get written up. But in those cases, publication bias isn’t really a problem, because the results face a decent shot of getting published anyway. Indeed, preprint servers aren’t really intended to be an archive for work that can’t be published in traditional outlets; instead, they are more like a parking spot for papers that are being shopped for publication in traditional outlets. Hence, the relatively small difference between effect sizes in gray literature and journals.
Preprints and p-hacking
Franco, Malhotra, and Simonovits (2014) suggest that papers in the social sciences don’t get written up and posted to a preprint server if the results don’t look publishable. Brodeur, Cook, and Heyes (2020) provide some complementary evidence that when authors engage in p-hacking, they do it in anticipation of the challenges of publication, not in response to pushback from peer reviewers.
Brodeur, Cook, and Heyes (2020) look for the statistical fingerprints of p-hacking in economics journals versus working papers. They’re able to detect this because p-hacking leaves a different statistical fingerprint than regular publication bias. Imagine a bunch of results are plotted in a scatterplot, like in the left-most figure below, with effect sizes on the horizontal axis and the imprecision of the estimate on the vertical axis. Everything in the red triangle is not statistically significantly distinguishable from zero (the red zone widens as you go up, because as imprecision gets larger, larger and larger estimates could actually be consistent with the true effect size being zero).
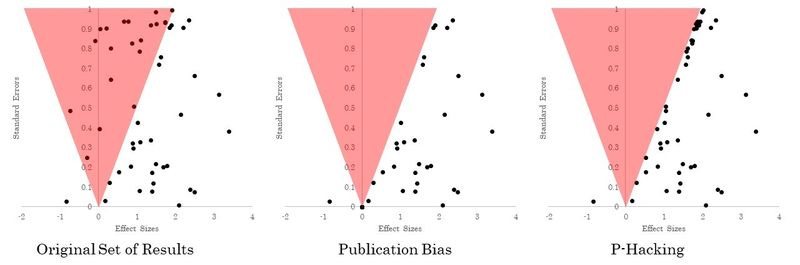
In the middle figure, we illustrate the statistical footprint of publication bias: all the results in the red triangle just disappear, because they don’t get published. (I talked about how to detect his here) In the right figure, we have the statistical footprint of p-hacking. Instead of disappearing, all the effects in the red triangle get perturbed again and again until they lie outside the red triangle. This leads to a suspicious pile of results that just (barely) happen to be statistically significant and therefore publishable.
Brodeur, Cook, and Heyes (2020) look for this kind of suspicious pileup right above the conventional thresholds for statistical significance. The figures below plot the distribution of something called a z-statistic, which divides a normalized version of the effect size by an estimate of precision. A big z-statistic is associated with a precisely estimated effect that is large - those are places where we can be most confident the true effect is not actually zero. A small z-statistic is a small and very imprecisely effect size; those are places where we worry a lot that the true effect is actually zero and we’re just observing noise. The figure on the left presents z-statistics from the main results of every empirical paper published in a top 25 economics journal in 2015 and 2018. The figure on the right presents the same thing for the preprint version of each of these papers.
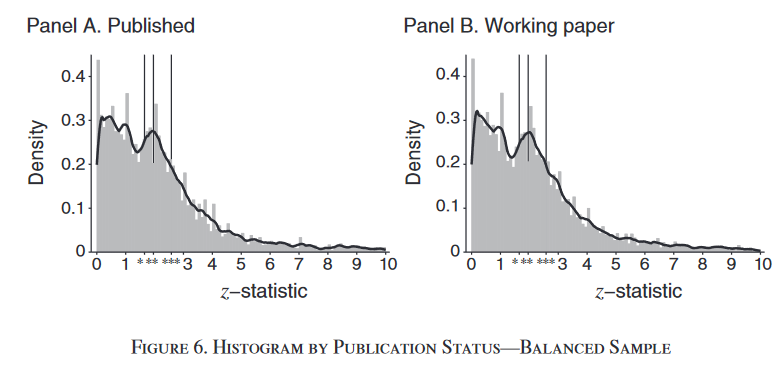
Notice there’s a big hump in the middle; that’s the suspicious pileup I discussed above. Lots of papers are publishing results that are just barely statistically significant. Hmmmmmmm, how convenient. But in the current discussion, the main point is that this bump is already there in the working paper stage. If we interpret this as evidence of p-hacking, it’s telling us that researchers don’t do it when reviewers complain - they do it before they even submit to reviewers.
(Aside - It’s also notable that peer review doesn’t seem to do much to dampen this bump; we might therefore conclude that peer review fails to detect p-hacking. But hold on… it could also be that the cases where peer review sniffs out p-hacking just aren’t published!)
What’s the credit for a preprint?
Now, before we draw strong conclusions about the efficacy of preprint servers for reducing publication bias, we should pause to note that a journal may provide professional credit that a preprint does not. Franco, Malhotra, and Simonovits’ result about null results never even being written up suggests it might not be worth writing up a draft merely to post it on a preprint server. But it might be worth writing up a draft if it would result in a peer reviewed journal article. You can at least list that on your CV under published and peer reviewed papers, and maybe it helps you get tenure.
Maybe that’s enough to pull null results out of the file drawer and into the public domain. But in science, a successful publication is not just one that gets published - it’s one that is influential. One proxy we can use for that is the number of citations received. And when Fanelli, Costas, and Ioannidis look at the impact of citations on bias, they find the same kind of effect as they do for publication. More cited work tends to exhibit bigger effect sizes, though again, the overall effect is pretty small.
Change methodologies or publication outlet?
Taken all together, I suspect the opportunity to publish null results somewhere won’t make a huge difference to the prevalence of p-hacking, so long as researchers continue trying to make big and bold discoveries. That kind of ambition seems likely to always provide an incentive to abandon projects that seem unlikely to deliver those kinds of results, and also to draw researchers to methods that seem to deliver them. But that doesn’t mean it’s hopeless.
Brodeur, Cook, and Heyes’ results on p-hacking in economics also found something else quite interesting. It turns out, the extent of p-hacking varies a lot by methodology. Check out the following figure, which tries to measure how the extent of p-hacking in different methods.

Whereas there’s no significant difference between preprints and publications, there are quite large differences among economic methods. Brodeur, Cook, and Heyes argue something like 16% of statistically insignificant results in papers using instrumental variables are shifted into the significant range (upper right figure), but only 1.5% of insignificant results using randomized control trials are (lower left).
That suggests methodological changes might be able to make a big dent in some of these problems. We’ll turn to one such methodological innovation - preanalysis plans - in a future newsletter.
If you liked this, you might also like:
Or, subscribe:






Share this post