

How did we end up in a situation where so many scientific papers do not replicate? Replication isn’t the only thing that counts in science, but there are lots of papers that, if they actually describe a regularity or causal mechanism in the world, then we should be able to replicate it. And we can’t. How did we get here?
One theory (not the only one), is that the publish-or-perish system is to blame.
In an influential 2016 paper, Paul Smaldino and Richard McElreath simulated science in action with a simple computer simulation. Their simulation is a highly simplified version of science, but it captures the contours of some fields well. In their simulation, “science” is nothing but hypothesis testing (that is, using statistics and data to assess whether the data is consistent or inconsistent with various hypotheses). One hundred simulated labs pursue various research strategies and attempt to publish their results. In this context, a “research strategy” is basically just three numbers:
A measure of how much effort you put into each research project: the more effort you put in, the more accurate your results, but the fewer projects you finish
A measure of what kinds of protocols you use to detect a statistically significant event: you can trade off false negatives (incorrectly rejecting a true hypothesis) and false positives (incorrectly affirming a false one)
The probability you choose to replicate another lab’s findings or investigate a novel hypothesis
At the end of each period, labs either do or do not finish their project. If they do, they get a positive or null result. They then attempt to publish what they’ve got. Next, a random set of labs is selected and the oldest one “dies.”
Over time, labs accumulate prestige (also a number) based on their publishing record. Prestige matters because at the end of every period, the simulation selects another set of random labs. The one with the highest prestige spawns a new lab which follows similar (though not necessarily identical) research strategies as it’s “parent.” This is meant to represent how successful researchers propagate their methods via training postdocs who go on to form their own labs or via imitation of their methods by new labs who attempt to emulate prestigious work.
Lastly, Smaldino and McElreath assume prestige is allocated according to the following rules:
Positive results are easier to publish than null results
More publications leads to more prestige
Replications give less prestige than novel hypotheses
What happens when you simulate this kind of science is not that surprising: labs with low effort strategies that adopt protocols conducive to lots of false positives publish more often then those that try and do things “right.” Let’s call this kind of research strategy “sloppy” science. Note that it may well be that these labs sincerely believe in their research strategy - there is no need in this model for labs to be devious. But by publishing more often, these labs become more prestigious and over time they spawn more labs, so that their style of research comes to dominate science. The result is a publication record that is riddled with false positives.
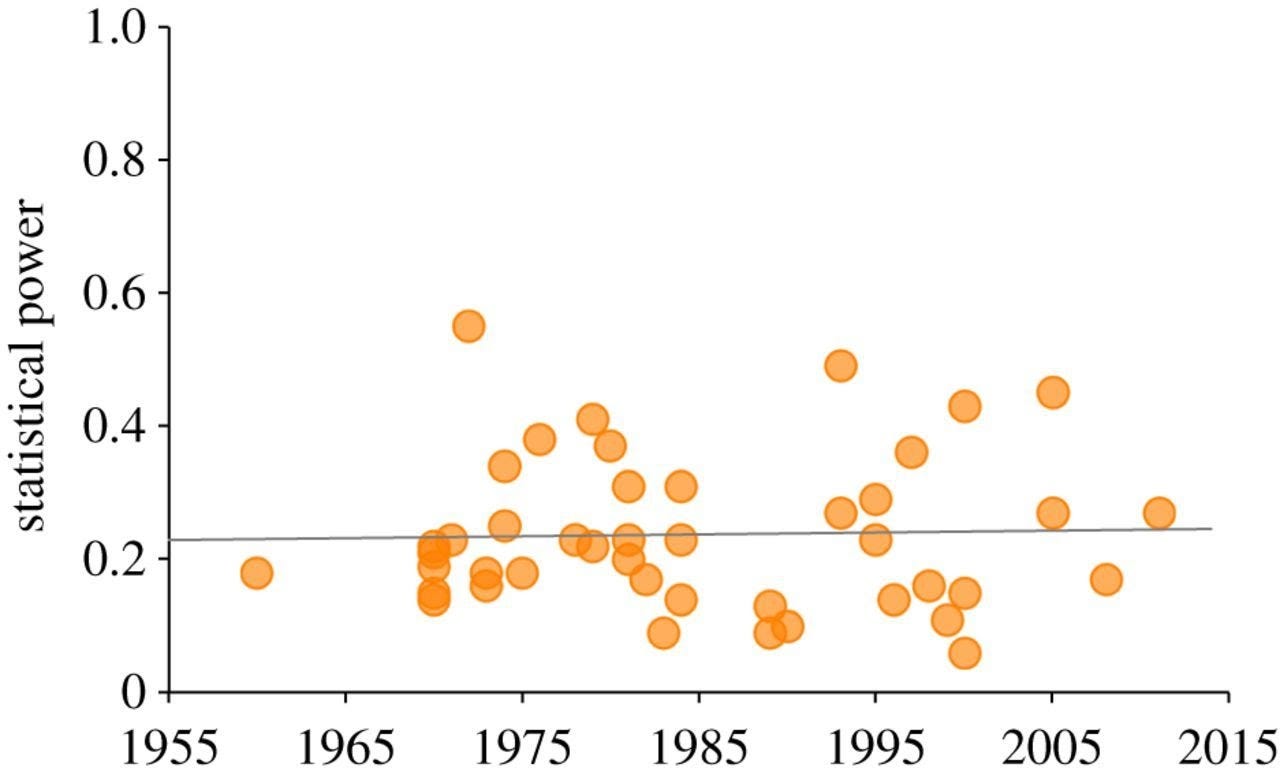
In short, Smaldino and McElreath suggest the incentive system in science creates selective pressures where people who adopt research strategies that lead to non-replicable work thrive and spread their methods. If these selective pressures don’t change, no amount of moral exhortion to do better will work; those who listen will always be outcompeted by those who don’t, in the long run. In fact, Smaldino and McElreath show that, despite warning about the poor methodologies in behavioral science that date back to at least the 1960s, in 44 literature reviews (see figure below) there has been no increase in the average statistical power of hypothesis tests in the social and behavioral sciences.
Is it a good model?
Smaldino and McElreath’s simulation suggests it’s the incentive schemes (and their effect on selection) we currently use that lead to things like the replication crisis. So what if we changed the incentive system? Two recent papers look at the conduct of science for projects that are just about identical, except for the incentives faced by the researchers.
First, let’s take a look at a new working paper by Hill and Stein (2020). Smaldino and McElreath basically assert that the competition for prestige (only those with the most prestige “reproduce”) leads to a reduction in effort per research project, which results in inferior work (more likely to be a false positive). Hill and Stein document that this is indeed the case (at least in one specific context): competition for prestige leads to research strategies that produce inferior work fast. They also show this doesn’t have to be the case, if you change the incentives of researchers.
Hill and Stein study structural biology, where scientists try to discover the 3D structure of proteins using modeling and data from x-ray scattering off protein crystals. (Aside: this is the same field that was disrupted last week by the announcement that DeepMind’s AlphaFold had made a big leap in inferring the structure of proteins based on nothing more than DNA sequence data). What makes this setting interesting is a dataset that lets Hill and Stein measure the effort and quality of research projects unusually well.
Structural biology scientists report to a centralized database whenever they take their protein crystals to a synchrotron facility, where they obtain their x-ray data. Later, they also submit their final structures to this database, with a time-stamp. By looking at the gap between the receipt of data and the submission of the final protein model, Hill and Stein can see how much time the scientists spend analyzing their data. This is their measure of how much effort scientists put into a research project.
The database also includes standardized data on the quality of each structural model: for example, how well does the model match the data, what is the resolution of the model, etc. This is a key strength of this data: it’s actually possible to “objectively” rate the quality of research outputs. They use this data to create an index for the “quality” of research.
Lastly, of course, since scientists report when they take their sample to a synchrotron for data, Hill and Stein know who is working on what. Specifically, they can see if there are many scientists working on the same protein structure.
The relevant incentive Hill and Stein investigate is the race for priority. There is a norm in science that the first to publish a finding receives the lion’s share of the credit. There are good arguments for this system, but priority can also lead to inefficiency when multiple researchers are working on the same thing and only the first to publish gets credit. In a best case scenario, this race for priority means researchers pour outsized resources into advancing publication by a few days or weeks, with little social benefit. In a worst case scenario, researchers may cut corners to get their work out more quickly and win priority.
Hill and Stein document that researchers do, in fact, spend less time working with their data to build a protein model, when there are more rivals working on the same protein at the same time. They also show this leads to a measurable decline in the quality of the models. Moreover, based on some rules of thumb about how good a protein model needs to be for application in medical innovation, this quality decline probably has a non-negligible impact on things non-scientists care about, like the development of drugs.

But wait, it gets worse. Why do some proteins attract the attention of lots of scientists, and others not? It’s not random. In fact, Hill and Stein provide evidence that the proteins with the most “potential” (i.e., the ones that will get cited the most in other academic papers when their structure is found) are the ones that attract the most researchers. (Aside: Hill and Stein do this with a LASSO regression that predicts the percentile citation rank of each protein based on the data available on it prior to its structure being discovered).
In short, the most interesting proteins attract the most researchers. The more intense competition, in turn, leads these researchers to shorten the time they spend on modeling the protein, in an attempt to get priority. That, in turn, leads to the most inferior modeling on the proteins we would like to know the most about.

Hill and Stein’s paper is about one of the downsides of the priority system. This is a bit different than Smaldino and McElreath, where prestige comes from the number of publications one has. However, in Smaldino and McElreath, their simulated labs can die at any moment, if they are the oldest one in a randomly selected sample. This means the labs that spawn are the ones who are able to rapidly accrue a sizable publication record - since if you can’t get one fast, you might not live to get one at all. As in Hill and Stein, one way labs do this is by cutting back on the effort they put into each research project.
Different Incentives, Different Results?
However, academics who are judged on their publication record aren’t the only people doing structural biology. “Structural genomics” researchers are “federally-funded scientists with a mission to deposit a variety of structures, with the goal of obtaining better coverage of the protein-folding space and mak[ing] future structure discovery easier” (Hill and Stein, p. 4). Hill and Stein argue that this group is much less motivated by publication than the rest of the structural biology. For example - only 20% of the proteins they work on end up with an associated academic paper (compared to 80% for the rest of structural biology). So if they aren’t driven by publication, is the quality of their work different?

Yes! Unlike the rest of structural biology, on average this group is likely to spend more time on proteins with more potential. In the above diagram, they are the red line, which slopes up. And while the quality of the models they generate for highest potential proteins is still a bit lower than the low potential ones, the strength of this relationship is much smaller than it is for those chasing publication.

One other recent study provides some further suggestive evidence that different incentives produce different results - or at least, the perception of different results. Bikard (2018) looks at how research produced in academia is viewed by the private sector, as compared to research produced by the private sector (think papers published by scientists working for business). Specifically, are patents more likely to cite academic or private sector science?
The trouble is this will be an apples-to-oranges comparison if academia and the private sector focus on different research questions. Maybe the private sector thinks academic research is amazing, but simply not relevant to private sector needs most of the time. In that case, they might cite private sector research at a higher rate, but still prefer academic research whenever it is relevant.
To get around this problem, Bikard identifies 39 instances where the same scientific discovery was made independently by academic and industry scientists. He then shows that patents tend to disproportionately cite the industry paper on the discovery, which he argues is evidence that inventors regard academic work skeptically, as compared to work that emerges from industry research.
To identify these cases of simultaneous discovery, Bikard starts with the assumption that if two papers are consistently cited together in the same parenthetical block, like so - (example A, example B) - then they may refer to the same finding. After identifying sets of papers consistently cited together this way, he provides further supporting evidence that this system works. He shows the sets of “twin” papers he locates are extremely similar when analyzed with text analysis algorithms, that they are almost always published within 6 months of each other, and that they are very frequently published literally back-to-back in the same journal (which is one way journals acknowledge simultaneous discovery).
This gives Bikard a nice dataset that, in theory, controls for the “quality” and relevance of the underlying scientific idea being described in the paper. This provides a nice avenue for seeing how academic work is perceived, relative to industry. When an inventor builds on the scientific discovery and seeks a patent for their invention, they can, in principle, cite either paper or both since the discovery is the same either way. But Bikard finds papers that emerge from academia were 23% less likely to be cited by patents than an industry paper on the same discovery.
This preference for industry research could reflect a lot of things. But Bikard goes on to interview 48 scientists and inventors about all this and the inventors consistently say things like the following, from a senior scientist at a biotechnology firm:
The principle that I follow is that in academia, the end game is to get the paper published in a as high-profile journal as possible. In industry, the end game is not to get a paper published. The end game is getting a drug approved. It's much, much, much harder, okay? Many, many more hurdles along the way. And so it's a much higher bar - higher standards - because every error, or every piece of fraud along the way, the end game is going to fail. It's not gonna work. Therefore, I have more faith in what industry puts out there as a publication.
So, to sum up, we’ve got evidence that non-academic consumers of science pay more attention to the results that come from outside academia, with some qualitative evidence that this is because academic science is viewed as lower quality. We’ve also got good data from one particular discipline (structural biology) that publication incentives lead to measurably worse outcomes. I wish we had more evidence to go on, but so far what we have is consistent with the simple notion that different incentive systems do seem to get different results in a way that moral exhortation perhaps does not.
But maybe you already believed incentives matter. In that case, one nice thing about these papers is they provide a sense of the magnitude of how bad academic incentives screw up science. From my perspective, the magnitudes are large enough that we should try to improve the incentives we have, but not so large that I think science is irredeemably broken. Hill and Stein find the impact of priority races reduces research time from something like 1.9 years to 1.7 years, not from 1.9 years to something like 0.5 years. And though the quality of the models generated is worse, Hill and Stein do find that, in subsequent years, better structure models eventually become available for proteins with high potential (at significant cost in terms of duplicated research). And even if inventors express skepticism towards academic research, they still cite it at pretty high rates. We have a system that, on the whole, continues to produce useful stuff I think. But it could be better.
If you thought this was interesting, you might also like these posts:





