
What does peer review know?
It knows a bit!
Like the rest of New Things Under the Sun, this article will be updated as the state of the academic literature evolves; you can read the latest version here.
You can listen to this post above, or via most podcast apps here.
Note: Have an idea for a research project about how to improve our scientific institutions? Consider applying for a grant of up to $10,000 from the Metascience Challenge on experiment.com, led by Paul Niehaus, Caleb Watney, and Heidi Williams. From their call for proposals:
We're open to a broad set of proposals to improve science -- for example, experimental designs, surveys, qualitative interviews with scientists, pilot programs for new mechanisms, scientific talent development strategies, and other research outputs that may be relevant for scientific research funders.
The deadline to apply is April 30. On to our regularly scheduled programming!
People rag on peer review a lot (including, occasionally, New Things Under the Sun). Yet it remains one of the most common ways to allocate scientific resources, whether those be R&D dollars or slots in journals. Is this all a mistake? Or does peer review help in its purported goal to identify the science most likely to have an impact and hence, perhaps most deserving of some of those limited scientific resources?
A simple way to check is to compare peer review scores to other metrics of subsequent scientific impact; does peer review predict eventual impact?
A number of studies find it does.
Peer Review at the NIH
Let’s start with peer review at the stage of reviewing research proposals.
Li and Agha (2015) looks at more than 100,000 research projects funded by the NIH over 1980-2008, comparing the percentile rank of the application peer review scores to the outcomes of these research projects down the road. For each grant, they look for publications (and patents) that acknowledge the grant’s support. Besides counting the number of publications and patents each grant results in, they can also see how often the publications are cited. Note, they are only looking at projects that actually were funded by the NIH, so we don’t need to worry that their results are just picking up differences between funded and unfunded projects.
The upshot is, better peer review scores are correlated with more impact, whether you want to measure that as the number of resulting journal articles, patents, or citations. For example, here’s a scatter plot of the raw data, comparing peer review percentile ranks (lower is better) to citations and publications. Lots of noise, but among funded projects, if people think your proposal is stronger, you’re more likely to get publications and citations.
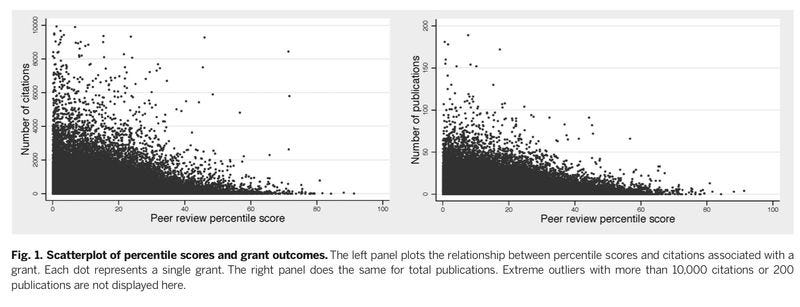
Li and Agha also look at the correlation between peer review scores and impact measures after controlling for other potentially relevant factors, such as the year or field of the grant, or the PI’s publication history, institution, and career characteristics. The results are moderated a bit, but basically still stand - compare two grants in the same year, in the same study section, from PIs who look pretty similar on paper, and the grant with higher peer review scores will tend to produce more papers, patents, receive more citations, and produce more very highly cited papers.
Among funded proposals, the predictive power of peer review seems to be highest at the top; the difference in citations, for example, between a top-scoring proposal and one at the 20th percentile tends to be much larger than the difference in citations between one at the 20th and 40th percentile.1 Moreover, even at the top, the correlation between peer review scores and outcomes isn’t great. If you compare proposals that score at the top to proposals at the 10th percentile (of grants that were ultimately still funded), the top proposal is twice as likely to result in a one-in-a-thousand top cited paper. I think that’s not actually that high - since a 10th percentile proposal isn’t that far off from the average, if peer review was really accurate, you might have expected the top proposal to be something like ten times as likely to produce a hit paper than as an average proposal.
Park, Lee, and Kim (2015) exploits a peculiar moment in NIH history to provide further evidence that the NIH peer review processes, on average, pick projects with higher scientific impact. In 2009, the US government passed the American Recovery and Reinvestment Act, a stimulus bill meant to fight the economic headwinds of the 2008 financial crisis. The bill authorized $831bn in new spending, of which a tiny corner, $1.7bn, was used by the NIH to fund research projects that would not normally have been funded. This provides a rare opportunity to see how good projects that would otherwise have been rejected by the NIH (which relies heavily on peer review to select projects) fare when they unexpectedly receive funding.
When Park, Lee, and Kim (2015) compare stimulus-funded proposals (which got lower peer review scores) to normally funded proposals, they find the stimulus-funded proposals tend to lead to fewer publications and that these publications tended to receive fewer citations. On average, a research proposal with peer review scores high enough to be funded under the NIH’s normal budget produces 13% more publications than a stimulus funded project. If we focus on a proposal’s most high-impact publication (in terms of citations), Park and coauthors find proposals funded only because of the stimulus got 7% fewer citations. Lastly, we can look at the 5% of publications funded by these NIH grants that received the highest amount of citations. A normally funded research proposal had a 7% chance of producing one of these “highest impact” papers; a stimulus-funded proposal had a 4% chance of producing one.
I think these results are pretty consistent with Li and Agha (2015) in a few ways. They replicate the general finding that in the NIH, higher peer review scores are associated with more research impact (as measured with imperfect quantitative methods). But they also find peer review doesn’t have super forecasting acumen. Note that Park, Lee, and Kim are not comparing proposals that just barely clear the NIH’s normal funding threshold to proposals that just barely miss it - they don’t have the data needed for that. Instead, they are comparing the entire batch of proposals rated above the NIH’s normal funding threshold to a batch of proposals that fall uniformly below it. The batch of normally funded proposals includes the ones that were rated very highly by peer review, which Li and Agha’s work suggests is where peer review tends to work best. Even so, the differences Park, Lee, and Kim find aren’t enormous.
Peer Review at Journals
We have some similar results about the correlation between peer review scores and citations at the publication stage too. As discussed in more detail in Do academic citations measure the impact of new ideas? Card and DellaVigna (2020) have data on about 30,000 submissions to four top economics journals, including data on their peer review scores over (roughly) 2004-2013. Because, in economics, it is quite common for draft versions of papers to be posted in advance of publication, Card and Dellavigna can see what happens to papers that are accepted or rejected from these journals, including how many citations they go on to receive (both as drafts and published versions). As with Li and Agha (2015), they find there is indeed a positive correlation between the recommendation of reviewers and the probability a paper is among the top 2% most highly cited in the journal.

Neither is this because high peer review scores lead to publication in top economics journals (though that’s also true). Card and Dellavigna also track the fate of rejected articles and find that even among rejects to these journals, those that get higher peer review scores still go on to receive more citations.
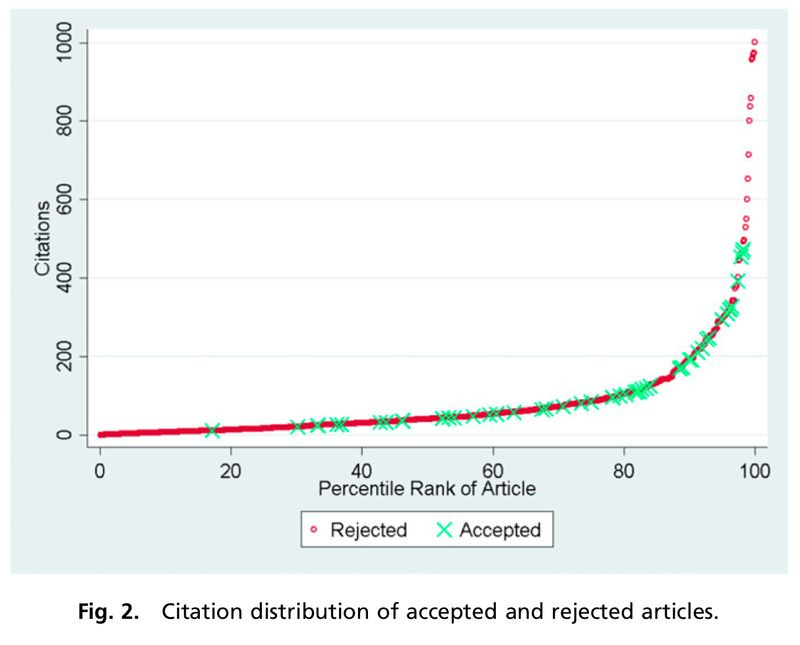
Siler, Lee, and Bero (2014) obtain similar results using a smaller sample of submissions to the Annals of Internal Medicine, the British Medical Journal, and The Lancet over 2003 and 2004. For a sample of 139 submissions that received at least two peer review scores, they can track down the eventual fate of the submission (either published in one of these three journals or another). Among the 89 peer-reviewed submissions that were ultimately rejected, the peer review scores (from the first, initial review) were positively correlated with the number of citations the submissions eventually received, though the correlation was pretty weak. For the 40 submissions that were reviewed and accepted, again positive (initial) peer review reports were positively correlated with the number of citations eventually received. In this latter case, the correlation was too weak to be confident it’s not just noise (possible because the sample was so small).
Siler, Lee, and Bero also emphasize that the three journals actually rejected the 14 papers that would go on to receive the most citations (though they did manage to get the 15th!).
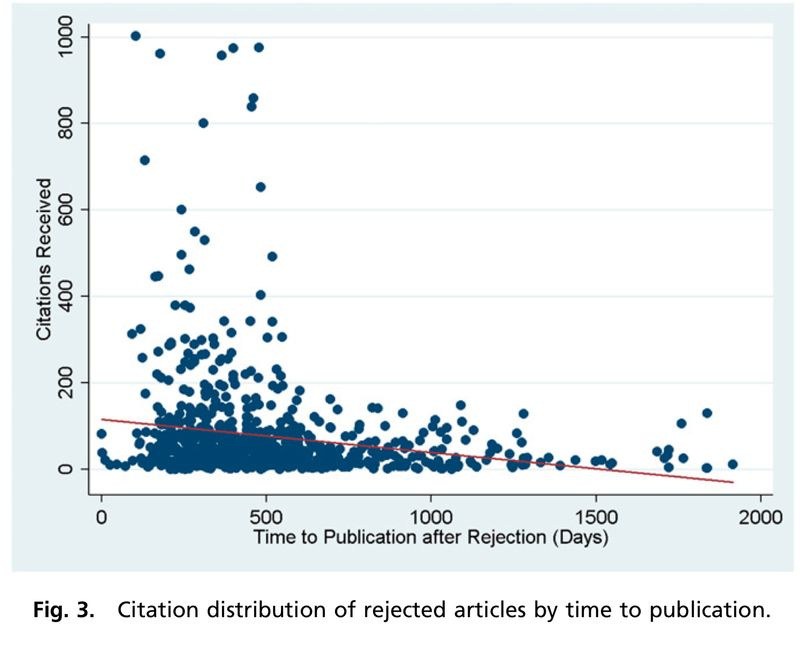
Perhaps more reassuring is the fact that generally speaking, papers that went on to be highly cited tended to be identified as publishable in other journals pretty quickly. The figure below compares the eventual number of citations received to the time elapsed between submission to one of the three journals under study and eventual publication somewhere else. No highly cited papers took longer than 500 days (not great, but better than 2000!) to find a home. That could be because peer review at one of the next journals the paper was submitted to was quick to recognize the quality of these articles, or possibly that they rapidly resubmitted after getting favorable feedback from initial peer reviewers. But this evidence is pretty indirect and other explanations are also possible (for example, maybe the authors believed in the paper’s merit and submitted them more frequently for review, or they were more frequently desk-rejected and so could be resubmitted fast).
That said, we also have one more study looking at peer review reports and eventual impact, this time in the American Sociological Review. Teplitskiy and Bakanic (2016) have data on 167 articles published in the American Sociological Review in the 1970s, as well as their peer review scores. Among this set of published article, they find no statistically significant relationship between peer review scores and the number of citations papers go on to earn.
After analyzing a sample of peer review reports, they argue this is because, for the American Sociological Review, reviewers simply don’t seem to be that focused on the likely impact of submitted papers. None of the reviews explicitly talk about the citation prospects of a paper, and some plausible related ideas don't seem to be much discussed either. For example, we might think the choice of topic is an important determinant of eventual impact, but in their analysis of reviews, only around 20% of positive comments (which were rare) or 6% of negative comments focused on the choice of topic. The vast majority of comments focused instead on general impressions (“this is a nice article”), the soundness of the argument, or concrete criticisms, which don’t seem directly tied to any attempt to predict the likely future impact of an article.
Interpret with Care
I think the above studies find reasonably consistent results. If you have a lot of data - thousands of papers or applications - you can confidently pick out the peer review signal from the noise: stronger peer review scores are correlated with subsequent measures of impact. The Li and Agha (2015) study, which draws on the largest dataset, also finds peer review is predictive after controlling for a lot of other observable variables.
These studies also find the signal of peer review isn’t too strong though. The best we can do is pick something with maybe twice the probability of being a hit, relative to averages (though, that’s averages of funded projects - maybe peer review does a better job of keeping resources away from really bad ideas). When we have less data, as with Siler, Lee, and Bero (2015), or Teplitskiy and Bakanic (2016), the strength of the association may be too weak to reliably be detected. Part of that may simply be down to the noise in citations (in another article, I argued they are very noisy measures of the “value” of articles), which will tend to pull estimated correlations towards zero, compared to what they would be if we could properly measure. But plenty of other papers use citations as well, and find stronger relationships between what they’re interested in and eventual citations. I think that suggests the noise and imprecision of peer review is not purely down to issues with citation data being too noisy to sniff out a strong relationship.
Thanks for reading! As always, if you want to chat about this post or innovation in generally, let’s grab a virtual coffee. Send me an email at matt.clancy@openphilanthropy.org and we’ll put something in the calendar.
In fact, a reanalysis of this data by Fang, Bowen, and Casadevall (2016) argues peer reviews are not predictive at all outside the very top few percent. My best guess at their divergent result depends on modeling citations in levels, instead of in log-levels. For highly skewed data like citations, I think log-levels is probably a better modeling choice, so ultimately I prefer Li and Agha’s approach, though I think both find peer review scores are not super informative. See also Li and Agha’s comment on Fang, Bowen, and Casadevall (click comments on the article).