


Literature Reviews and Innovation
Let's get meta
This article will be updated as the state of the academic literature evolves; you can read the latest version here. A podcast version will be released next week (traveling this week).
Special thanks to Yian Yin for pointing me to Haustein, Costas, and Lariviére (2015) and Fang et al. (2020).
We here at New Things Under the Sun are big fans of literature reviews. In a world where perhaps ideas are getting harder to find because of the burden of knowledge, it sure seems like literature reviews, that curate and synthesize a large volume of work, must be an important. But is that true? What do we really know about the effects of literature reviews on science and innovation?
Do People Read Literature Reviews?
One indicator of the importance of literature reviews is how well they get cited relative to traditional articles. If they tend to be highly cited, that’s one sign that they’re an important part of the knowledge ecosystem (though obviously not decisive on its own).
To assess that, we can pull data from Haustein, Costas, and Lariviére (2015), which counts short-run academic citations1 to both traditional and review articles published in 2012. Using the altmetrics database, it also tracks a variety of other indicators; we’ll look at mainstream media mentions, which are part of how research results get communicated to the public at large. Lastly, I’m particularly interested in whether literature reviews are more informative for policy development. To get a handle on that, we can use Fang et al. (2020), which counts citations from 2.7mn policy documents to the academic literature. These policy documents are drawn from around the world, and include government, think tank, NGO, and IGO documents.
The following figure compares the average citations received by review articles to the average citations of traditional articles across three audiences: academia, the policy world, and mainstream media.

Across the three domains, review articles tend to be more highly cited, on average, than original research. Within academia, review articles are cited by other academic publications at a rate about 2.3x that of traditional articles, at least for this sample of publications from 2012. Reviews are also more highly cited by the policy world, with review articles receiving on average 1.8x as many cites from policy documents per article as traditional articles. Among the mainstream media, the two are cited at the same rate. You get similar results when you look at the probability a particular article type is cited.
(One thing the above figure obscures is the vast differences in citation rates across audiences; the policy world cites review and traditional articles at roughly 10-20x the rate the mainstream media does, and the academic world cites them at 30-40x the rate of the policy world!)
There are some caveats to the above. How review articles are identified in academic databases is the subject of some controversy. Moreover, normally it is desirable to normalize citation counts by field; it’s easier to get many more citations, for example, in a field that is very large, compared to one that is very small. If fields differ systematically in their size and how much they use reviews, or in how difficult it is to correctly classify reviews, then that could make the aggregate data above misleading.
In an appendix to this post, I dig into these issues a bit. I don’t think they change any of the substantive conclusions though, so I omit them from the main text. My bottom line is that review articles are significantly more highly cited than traditional articles, on average, in academia and among the policy world. But citation does not necessarily signify genuine influence.2 Let’s turn to some of the (scant) evidence we have on the genuine influence of reviews.
Literature Reviews and Field Formation
We’ll begin with academia. McMahan and McFarland (2021) argue that one of the effects of literature reviews is to draw together work scattered across different microcommunities, often via highlighting the role of papers that can act as bridges between multiple niche communities.
To illustrate their argument, let’s start with an example (from their paper). In the figure below, we have two networks representing a field of climate science. This figure represents a lot of information. In each of these networks, the nodes represent papers cited by a specific review article (“Integrated Assessment Models of Global Climate Change”, published in the Annual Review of Energy and the Environment in 1997). The bigger the node, the more citations the paper has received during a particular time period. In the figure, links between nodes represent how often these papers are cited together by other articles. This is an indication that they are about a topic that is somehow related. Finally, the figure covers two time periods. At left, we have the linkages between articles in climate science, during the seven years preceding publication of the review article that references all these publications. At right, the seven years after publication.
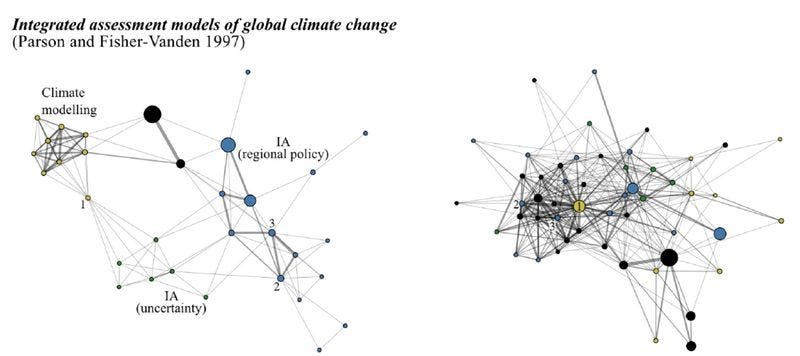
We can see how a field changes by studying the changes between these two networks. Let’s start with the network on the left. Prior to the publication of the review article, we can see a few different clusters of papers: one cluster (in blue) for integrated assessment models of regional policy; one cluster (in green) for integrated assessment models related to uncertainty; and one in yellow for climate modeling. That is, in the seven years preceding publication of this literature review, there were, roughly speaking, a few different sub communities that worked on different niche topics in climate modeling. We see this through the frequent co-citation of articles within each cluster and infrequent co-citations between clusters. If I’m writing about modeling uncertainty, I am likely to cite more than one of the papers in the uncertainty cluster, but less likely to cite any papers in the climate modeling cluster.
After the review is published, we no longer see these three distinct clusters. Instead, we have moved towards one denser cluster with more of a hub and spoke structure. Papers from the various original clusters are now frequently co-cited with papers in formerly separate clusters, and especially with a few major papers, which previously bridged different clusters. This is most clear for paper 1, which in the left figure is not highly cited, but is co-cited with papers in two different clusters and has now become highly cited. After the review, it’s now the central hub of a dense network of papers.
McMahon and McFarland show this kind of pattern isn’t an anomaly specific to climate science, but a pattern that broadly follows the publication of a review article. They build a dataset based on all the Annual Review articles published between 1990 and 2016, as well as all the articles published in a set of more than 1,000 major journals. The set of articles published in Annual Review journals forms their set of literature reviews, since this journal series specializes in review articles. They then use some statistical analyses to establish some reliable statistical associations. After an Annual Review article is published:
The network of cited articles is divided into fewer distinct clusters
The number of steps in a chain of citation between two different papers shrinks (for example, because most papers are now co-cited with at least one major hub paper)
Most papers start to receive fewer citations, but a small number start to receive more
Those three traits largely match the consolidation dynamics in the illustration: less separation into distinct clusters, and a few papers emerging as central hubs (with the rest perhaps a bit left behind).
That doesn’t necessarily prove that is was the Annual Review article that caused these changes though. It’s quite plausible that these dynamics are merely the natural evolution of fields. Maybe Annual Review articles merely act as records of processes that are underway with or without them, much in the way that newspapers record the great events of the day without causing them.
Ideally, we would want to run an experiment, where we get Annual Reviews to commission a bunch of literature reviews, but then randomly publish only some of them. We could then compare the evolution of the network structure of cited references in the published and unpublished articles.
McMahan and McFarland can’t do that; but they try the next best thing, which is to at least identify sets of cited articles that look like they could be the target of an annual review article, but which do not in fact get one (maybe for random reasons). Let’s call these the reviewed and unreviewed networks. If both reviewed and unreviewed networks look the same before Annual Review articles are published, and different afterwards, then that’s some evidence the Annual Review publication induced the change.
To identify a set of unreviewed networks that closely resemble reviewed networks (prior to publication), they look at the citation networks of traditional articles. Specifically, they identify a subset of articles whose co-citation networks resemble the co-citation networks of the cited references in an Annual Review article, in terms of the number of clusters and length of citation paths between papers, and where the cited documents also are of a similar “age” and receive similar numbers of citations as in the reviewed set. McMahan and McFarland then look at how the reviewed and unreviewed co-ciation networks evolve in the wake of an Annual Review article being published (for the reviewed networks) or a traditional article (for the unreviewed). They find the consolidation pattern following publication of a review article (described above) is much more apparent for the reviewed than the unreviewed.
This is encouraging, but it’s a very difficult problem to tackle with observational data. McMahan and McFarland have tried to identify networks of cited references that “resemble” each other, but we don’t know if there were subtle differences that can’t be picked up with their quantitative approach, but which might be apparent to people in the field.
The challenge of identifying otherwise identical controls is why an experiment that simply randomized which Annual Review articles get published would be so appealing. We don’t have such an experiment, but Thompson and Hanley (2019) does something similar.3 They commission graduate students to write 98 wikipedia articles on econometrics and chemistry. They then randomly publish half of the studies to wikipedia and look for changes in the published academic literature among papers on similar topics to the published articles, as compared to the unpublished ones. As discussed in more detail here, while few researchers have the courage to cite wikipedia directly, you can indirectly infer that it is being read by examine what happens to the citations of academic articles that wikipedia cites. After all, if you cite an article you discovered by reading the wikipedia page, you don’t have to tell anyone you found it via wikipedia. Thompson and Hanley find the articles cited by published wikipedia articles go on to receive 91% more citations (in the broader academic literature) than the articles cited in unpublished wikipedia articles.
That makes me more confident that the publication of literature review articles really is at least somewhat causal. McMahan and McFarland see changes in the citation structure of fields in the wake of Annual Review articles, and the wikipedia experiment finds that publishing reviews can causally affect what gets cited. While wikipedia is not an academic journal it is highly read - much like Annual Review journals (see the appendix).
Policy Impact
Academic research isn’t only for academics though. We would presumably like our policymaking to also be based on evidence about what works, and literature reviews can in principle give a more accurate picture of what a scientific field has found. Do literature reviews therefore exert a stronger influence in policy-making than original research articles? As noted above, review articles are cited at about 1.8x the rate of original research by policy documents. But how much do those citations matter?
Nellis et al. (2019) isn’t about the influence of literature reviews per se, but it is about how policy-makers are influenced by multiple studies, as compared to single studies. Nellis and coauthors build on the Metaketa I initiative, which organized six different randomized control trial experiments, in six different countries, on the efficacy of voter information programs. Specifically, the Metaketa experiments investigate whether providing voters with information on the performance of candidates, affects voting behavior. As discussed more in detail in Dunning et al. (2019), these experiments consistently showed these voter information programs have no statistically detectable impact on voting behavior.
Nellis et al. (2019) conduct an experiment on 55 policy-makers who attended an evidence summit that revealed the results of these six Metaketa experiments. These policymakers were government officials, program officers at non-profits, and a small number of academics who worked in the fields of governance and democracy promotion. The experiment randomized the order in which participants heard information about the studies, and surveyed them throughout the day. This let them see how their beliefs evolved as they heard different sets of information (though by the end of the day, everyone had heard all the same thing). What will be interesting for us is to see how policymakers update their beliefs when hearing about many studies (analogous to the function of a literature review), compared to when they hear about a single study.
The results are a bit nuanced. In one arm of their experiment, some participants are randomized into hearing a presentation about a single Metaketa study and others heard a meta-analysis of studies.4 After hearing one of these presentations, attendees were asked how they would allocate a $1mn budget between three different programs: providing information to voters about politician performance, giving special training to politicians and bureaucrats, or funding nonpartisan election monitors. Those who saw the results of the meta-analysis allocated 10-20% less funding to the voter information provision program than those who saw the results of a single study. Recall that both the single study and the meta-analysis find these kinds of voter information programs do not produce detectable results, so this decline in support comes from the effect of seeing that this result holds across multiple studies in different contexts, rather than being from only one study. That suggests a broader academic literature can indeed influence policy-making more than single studies (though perhaps not as dramatically as one would hope).
Other results are more equivocal. Nellis and coauthors also try to elicit participant’s beliefs about the results of another metaketa study (which had been intentionally left out of the meta-analysis they viewed). This left-out study also finds voter information programs have no detectable impact on voting behavior. Policymakers who viewed the meta-analysis presentation were slightly more likely to correctly predict the left-out study would also find no impact, and slightly more confident in their prediction. But the differences between the group that saw a single study and a meta-analysis were not statistically significant.
My interpretation is that the difference between a literature review and a single study (finding the same results) is decent, but not great. Not so large, anyway, that it clearly shines through in a sample of 55 participants and only a few options on the survey (participants could predict programs would have either positive, negative, or no effect, and marked their confidence with a three point scale). But this comparison probably understates the effects of literature reviews. In general, literature reviews do not merely corroborate the findings of single studies. Instead, they often refute or nuance the results of individual studies. If we believe literature reviews are more accurate indicators of the likely effects of a policy, on average, then we would should want more literature reviews, even if they are no more influential than single studies, for the same reason that we want more accurate individual studies in general!
A Review of this Review
While we don’t have as much information as I would like on the impact of literature reviews, it seems to me we have at least some evidence to support the commonsense view that they play an important role in science and innovation. To begin, they’re cited at roughly twice the rate of original research, at least in the academic and policy worlds. In academia, they do appear to herald a process of consolidating previously isolated niches and curating a small (but more manageable?) number of papers that reflect more central ideas. An experiment with wikipedia also suggests reviews really can affect what people engage with, providing at least some reason to think the association between field changes and publication of a review isn’t totally spurious. Meanwhile, in the policy world, we have some evidence that policymakers take more seriously the results of a large literatures, though the effect sizes are not enormous.
Thanks for reading! As always, if you want to chat about this post or innovation in generally, let’s grab a virtual coffee. Send me an email at matt.clancy@openphilanthropy.org and we’ll put something in the calendar.
Specifically, it counts citations received through the end of 2013, so between 1 and 2 years after publication
For more on this issue, see my post Do academic citations measure the impact of new ideas? though note that post is mostly about how to interpret citation data for original research articles.
See Free Knowledge and Innovation for more on Thompson and Hanley (2019)
Actually, they leave one study out of the meta-analysis, so that as one of their questions they can ask respondents their beliefs about what that study will find.