
Do Academic Citations Measure the Impact of New Ideas?
Yes, but with some serious caveats
Like the rest of New Things Under the Sun, this article will be updated as the state of the academic literature evolves; you can read the latest version here.
You can listen to this post above, or via most podcast apps: Apple, Spotify, Google, Amazon, Stitcher.
A huge quantity of academic research that seeks to understand how science works relies on citation counts to measure the value of knowledge created by scientists. The basic idea is to get around serious challenges in evaluating something as nebulous as knowledge by leverage two norms in science:
New discoveries are written up and published in academic journals
Journal articles acknowledge related work by citing it
If that story works, then if your idea is influential, most of the subsequent knowledge it influences will eventually find its way into journal articles and then those articles will cite you. By counting the number of journal articles citing the idea, we have a rough-and-ready measure of it’s impact.1
This measure of scientific impact is so deeply embedded in the literature, that its absolutely crucial to know if it’s reliable. So today I want to look at a few recent articles that look into this foundational question: are citation counts a good measure of the value of scientific contributions?
What is Value?
Citations as a measure of academic value is a sensitive topic, so before jumping in, it’s important to clarify what value means in this context. There are at least two things that are bundled together.
First, there is what we might call the potential value of some discovery. Did the discovery uncover something true (or directionally true) about the universe that we didn’t know? If widely known, how much would affect what people believe and do? How would it be assessed by an impartial observer with the relevant knowledge set?
Second, there is the actual impact of the discovery on the world out there. Did the discovery actually affect what people believe and do? More specifically, did it affect the kinds of research later scientists chose to do?
If science is working well, then we would hope the only difference between these two is time. Optimistically, good ideas get recognized, people learn about them, incorporate the insights into their own research trajectories, and then cite them. In that case, potential value is basically the same thing as the actual impact if you let enough time pass.
But we have a lot of reasons not to be optimistic. Maybe important new ideas face barriers to getting published and disseminated, because of conservatism in science, or because of bias and discrimination. Or, if those obstacles can be surmounted, maybe there are barriers to changing research directions that prevent scientists from following up on the most interesting new ideas and allowing them to reach their potential. Or maybe low potential ideas garner all the attention because the discoverers are influential in the field.
In that case, citations still reflect actual impact, in the sense that they really do capture how ideas affect what people believe and do. But in this less optimistic scenario, impact and potential value have been partially or completely decoupled, because science isn’t very good at translating potential value into realized value. It lets good ideas go to waste and showers disproportionate attention on bad ones.
But it’s also possible that citations don’t even reflect actual impact. This would be the case, for example, if citations don’t really reflect acknowledgements of intellectual influence. Maybe people don’t read the stuff they cite; maybe they feel pressured to add citations to curry favor with the right gatekeepers; maybe they just add meaningless citations to make their ideas seem important; maybe they try to pass off other people’s ideas as their own, without citation. If these practices are widespread, then citations may not reflect much of anything at all.
I’m going to end up arguing that citations are reasonably well correlated with actual impact, and science works well enough that actual impact is also correlated with potential impact. That’s not to say there are no problems with how science works - I think there are plenty - but the system isn’t hopelessly broken.
Finally, bear in mind that my goal here is mostly to assess how useful are citation counts in the context of academic papers that study how science functions. That’s a context where we typically have a lot of data: always hundreds of papers, and usually thousands. With a lot of observations, even a small signal can emerge from a lot of noise. In contexts with many fewer observations though, we shouldn’t be nearly so confident that citations are so valuable. If you are trying to assess the contribution of a single paper, or a single person, you shouldn’t assume citation counts are enough. To get a better sense of value in this context, unfortunately you probably have to have someone with the relevant knowledge base actually read the paper(s).
OK, onward to what we find when we look into these questions.
Why do people cite papers?
The whole point of tracking citations is the assumption that people acknowledge the influence of previous discoveries by citing the relevant papers. Is that really what citations do though?
Teplitsky et al. (2022) tries to answer this question (and others) by asking researchers about why they cited specific papers. In a 2018 survey, they get responses from a bit over 9,000 academics from 15 different fields on over 17,000 citations made. Surveys are personalized, so that each respondent is asked about two citations that they made in one of their own papers. Teplitsky and coauthors construct their sample of citations so that they have data on citations to papers published in multiple years, and which span the whole range of citation counts, from barely cited to the top 1% most cited in the field and year. Among other things, the survey asks respondents “how much did this reference influence the research choices in your paper?”, with possible answers ranging from “very minor influence (paper would’ve been very similar without this reference)” to “very major influence (motivated the entire project).”
Assessed this way, most citations do not reflect significant influence. Overall, 54% of citations had either a minor or very minor influence. Given the way these options were explained to respondents, that’s consistent with most citations affecting something less than a single sentence in a paper. Only about 18% of citations reflect major or very major influence (for example, they influenced the choice of theory, method, or the whole research topic). That implies citations are a very noisy way of measuring influence.
But there’s an interesting twist. It turns out the probability a paper is influential is not random: more highly cited papers are also more likely to be rated as major or very major influences.
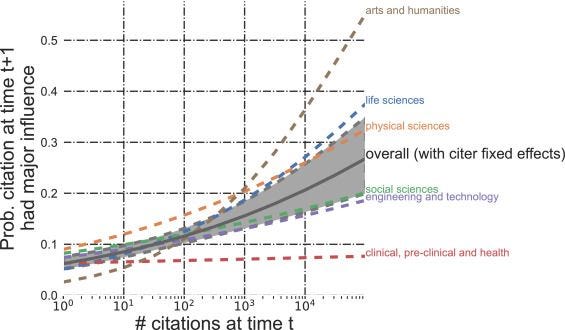
Notice the overall data line says “with citer effects.” That’s intended to control for the possibility that there might be systematic differences among respondents. Maybe the kind of researchers who lazily cite top-cited work are also the kind of people who lazily answer surveys and just say “sure, major influence.” But Teplitsky and coauthors survey is cleverly designed so they can separate out any potential differences among the kind of people who cite highly cited work versus those who do not: they can look at the probability the same person rates a paper as more influential than another if it also has more citations. Overall, when you additionally try to control for other features of papers, so that you are comparing papers papers the survey respondent knows equally well (or poorly), the probability they will rate a paper as influential goes up by 34 percentage points for every 10-fold increase in citations.
So I take a few things from this survey. First, there is a ton of noise in citation data; just as not all papers are equal, so too are not all citations equal. A paper with 5 citations is quite plausibly more influential than one with 10. But all else equal, there is a pretty strong relationship between the number of citations a paper gets and how influential it is. This measure is subject to a lot of noise, but among very highly cited papers, the relationship between citations and influence is actually stronger than it is for less cited papers. Not only is a paper with 1000 citations more likely to be influential than one with 500 simply because it has so many more chances to be influential, but additionally because each of those chances has a higher probability of being influential.
Uncited Influences
Note, however, that Teplitsky and coauthors start with citations: they observe a citation that was made and ask the citer why they made it. But that design means it’s impossible to identify work that is influential but uncited. Fortunately, new natural language processing techniques allow us to start answering that as well.
Gerrish and Blei (2010) propose a new method to measure the influence of academic papers by looking at how much they change the language of papers that come later. They then show that, indeed, if you try to identify influential papers merely based on the relationships between their text and the text of later articles, there is a reasonably strong correlation between language influence and citations.
Gerrish and Blei start with topic models. These are a way of modeling the words used in a paper as the outcome of a blind statistical process. We pretend there are these things out there called “topics” which are like bags of words, where you reach into the bag and pull out a word. Different topics have different mixes of words and different probabilities of grabbing specific words. Next, we pretend papers are nothing more than a bunch of words we grab out of different topic bags. As an example, if I’m writing a paper on the impact of remote work on innovation, then maybe half my words are drawn from the “remote work” topic bag and half from the “innovation” topic bag. The remote work bag has a lot of words like “zoom”, “dropbox”, and “distance”, and the innovation bag has a lot of words like “idea”, “patent”, and “knowledge.”
Gerrish and Blei use a more sophisticated version of this model, which allows the words associated with a topic to change over time. For example, in the year 2000, maybe the word “Skype” was pretty common in the “remote work” topic, but by 2020 it had been supplanted by “Zoom.”
Their big innovation is to model how these changes happen. It’s not random. Instead, they assume topics change each year so that the probability of drawing a certain word moves in a direction to more closely match the probability of finding it in the most influential papers published in the previous year on the topic. If my paper on innovation and remote work turns out to be highly influential, then next year papers on remote work and innovation are going to look more like my paper.
With this model in hand, Gerrish and Blei work backwards, starting with the full text of thousands of actually published papers in Nature, Proceedings of the National Academy of Sciences (PNAS), and the Association for Computational Linguistics Anthology (ACL). From there, they can infer what kinds of topics and influential papers that would best generate the data we actually observe.
The nice thing about this is it is a measure of how influential a paper is that is derived from data that is largely independent of citations. Influence is detected only by how much a paper anticipates changes in language in a field; at no point does the algorithm look at who is actually citing this supposedly influential paper. And the nice thing about language is it is a bit harder to fake. We know from the previous paper that lots of citations don’t reflect actual influence; it is possible to play the same kinds of games with the language you use, but it’s not easy. So this is plausibly a way to identify real influence, of a kind. It’s not a perfect measure either, because it completely misses out on influence that doesn’t result in changed language: a new database might be highly used and highly cited, but have little impact on paper language, for example.
But it turns out that there is correlation between influence, as measured by changes in text, and citations. The 20% most influential PNAS and ACL papers garner about 40% of all citations. The fit is even better for Nature, where the top 20% most influential papers get 60% of citations and the bottom 20% least influential get barely any citations. On the whole, the correlation between the percentile rank of citations and the percentile rank of influence is on the order of 0.2 to 0.35, which is real but pretty noisy.
Gerrish and Blei’s work is more like a proof of concept and has some issues. For example, if a paper in Science, not Nature, is highly influential and exerts a big influence on the language used on Nature articles, then their dataset will miss this. Gerow et al. (2022) builds on Gerrish and Blei in a few ways; one is taking this methodology to half a million abstracts in the American Physical Society and 2 million full-text documents in the JSTOR archive. In both setting, influence is again robustly correlated with citations, though again with a lot of noise.
Influence Beyond the Academy
So citations are correlated with two different measures of impact, though with substantial noise: academics say a citation is more likely to be influential in their own work if it is highly cited, and work that seems to change the language of later papers also tends to be more cited. Another important dimension of influence is influence outside of the academy: are highly cited papers more likely to have an impact on the progress of science and technology more generally?
Two recent papers find this is the case. Poege et al. (2019) finds that the most highly cited papers in academia are also more likely to be cited outside academia, in patents. In the figure below, the horizontal axis is the citation 3-year percentile rank of an academic article. From the right, the top 0.01% most highly cited papers (after three years), followed by the top 0.1% most highly cited, then the top 1% most highly cited and so on. The vertical axis is the probability the paper is cited by a patent. More highly cited papers are also more likely to be cited in patents.
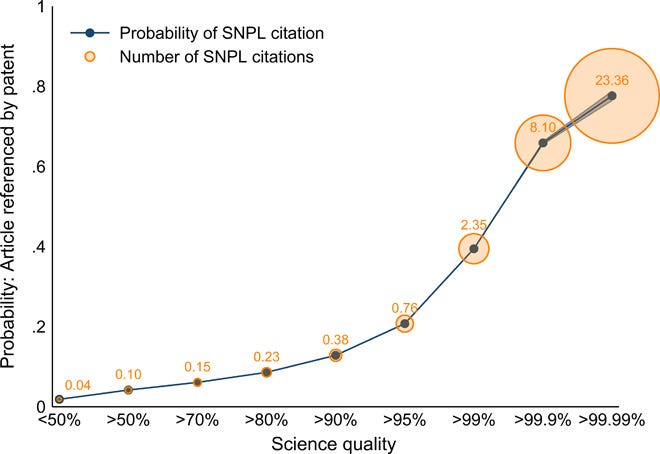
Yin et al. (2021) find the same kind of thing for patents: the citations made by patents are much more likely to be top cited papers, then would be the case if citation among academia was unrelated to citation in patents. If you pick a paper cited by patents at random, it has a 11% chance of being one of the top 1% most highly cited papers in science. But Yin et al. (2021) also show this result holds for other non-academic domains. They collect a large set of US government documents and try to sniff out references to academic work using natural language processing algorithms, identifying about 40,000 documents that cite the scientific literature. Here the effect is even stronger than it is for patents: a randomly selected paper that is cited by government documents has a 16% chance of being among the top 1% most cited academic papers.
Of course, we’ve got the same kind of problem with this data as we have for academic citations: how do we know these non-academic citations actually reflect influence? We have a few pieces of evidence that are suggestive.
First, whereas we might be worried that academics cite work they are not engaging in to curry favor with the right academic gatekeepers, this doesn’t seem to be as relevant for non-academic citations. Second, as discussed in the post “Science is Good at Making Useful Knowledge,” patents that cite highly cited academic work also tend to be more valuable patents themselves. That’s not what we would expect if the citations are not actually bringing any value, in terms of new knowledge. Moreover, we have some scattered evidence for the commonsense view that science really does add value to technology.
That said, it may still be that highly cited work is often used as a form of rhetorical armor, to make arguments that are not really influenced by the citation seem like they have a stronger evidentiary backing than they do (see, e.g., Von Neumann 1936) (actually, I made that last one up to illustrate the idea). We’ll see some evidence this might be the case below.
Does impact lead to citations, or do citations lead to impact?
The preceding is evidence that citation counts are at least correlated with genuine impact. That’s good enough for some purposes, but it would be useful to know if citations also pick up what I called the potential value of papers. Ideally, the best papers are read and have influence, and that influence is revealed to us by citation. But it’s also quite plausible that there is some reverse causation going on here: citations may cause more influence.
Teplitsky et al. (2022) provide some pretty compelling evidence this reverse causation is part of the story. First off, they show people are much more likely to be aware of a paper early in the course of a research project if it has been more highly cited. That makes sense; highly cited work is probably more likely to be talked about and taught in graduate schools, and is more likely to be discovered when you trawl through the citations of related projects. But that’s also a way that citations can lead to influence: you can’t be influenced by stuff you haven’t read. Teplitsky et al. (2022) also show respondents are more likely to report they know highly cited papers very well or extremely well. Again, that’s not surprising; people might feel they need to know about the highly cited work in their field. But it all means that highly cited work becomes a focal point that can more easily influence future research. Citations beget citations.
Teplitsky et al. (2022) also present some evidence that learning (or being reminded) that a work is highly cited can influence how people assess it. They embed an experiment into their survey, showing a subset of respondents information about a paper’s citation rank, before being asked to assess how influential it is. When a paper is not highly cited and people are reminded of that fact, they rate the paper’s quality as lower than respondents rating papers of similar citation rank, but who were not explicitly told about its citations. That would support the notion that citations can serve as rhetorical armor, as noted above, since merely being highly cited makes people perceive a paper more favorably. Recall the typical citation is not rated as having a major influence, even among very highly cited papers.
As far as I know, we lack similar evidence on why people cite academic work outside of academia. But I would be quite surprised if the same dynamics are not at play. I suspect highly cited papers are easier to discover and learn about, and hence to influence non-academic work, even if less cited work might have been more relevant. It may also be that they are viewed as more credible papers to base policy and technology on at the outset. I also bet highly cited papers serve as better rhetorical weapons than non-highly cited papers, though perhaps this effect is weaker outside academia, where most non-academic readers may have no idea how highly cited a paper is.
Do Citations Measure Potential Value Too?
For the reasons noted above, citations have some self-amplifying dynamics; once something is highly cited, it’s easier to discovery, and so more likely to become a genuine focus of future research effort. At the same time, discoverability and the enhanced credibility that come with extra citations probably also help get some extra citations that do not reflect genuine influence, but which make it yet easier to discover highly cited work. The self-amplifying nature of citations is one reason why the distribution of citations is also so unequal.
But a key question is what gets this amplification feedback loop going in the first place. Surely there is no small element of randomness here, but it’s not completely random. To tease this out, we would ideally like some indicators of a paper’s potential value as assessed shortly after the paper is complete, and before it has time to accumulate many citations, since these might influence subsequent assessments. One place we can get a lot of such data is from the peer review system.
Card and DellaVigna (2020) have data on about 30,000 submissions to four top economics journals, including data on their peer review scores and the editor’s decision regarding the submission, over (roughly) 2004-2013. Card and DellaVigna can also calculate how many citations each of these submissions ultimately gets, whether it is published in these journals, or other journals, or merely remains a working paper (which is not uncommon in economics). Below, we can see that there is indeed a positive correlation between the recommendation of reviewers and the probability a paper is among the top 2% most highly cited in the journal. Peer review reports predict the probability of having a hit paper.
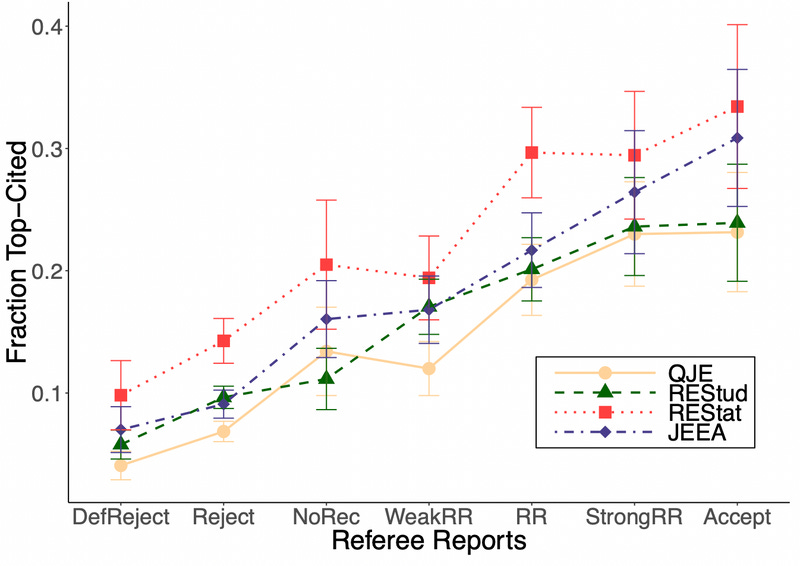
One might be concerned that a naive comparison like this is misleading because a paper’s eventual fate in the journal review process may also affect citations. Maybe all this shows is getting published in a top economics journals leads to more citations, and that is simply more likely to happen for papers that get favorable referee reports?
The paper presents a few pieces of evidence that strongly imply this is not the case. In the figure below, we break submissions out into two categories: those that are given a revise-and-resubmit at the journal, and those that are not. On the vertical axis, we have a measure of how many citations submissions go on to get. But on the horizontal axis, we are now summarizing the peer review reports in a different way from the previous figure. Instead of reporting the decision of a single peer reviewer, we’re going to aggregate all the peer review information together and combine it with a few other paper characteristics to estimate the probability it gets a revise-and-resubmit.

As the figure shows, even among papers that are ultimately rejected and not published in these journals, papers that get more favorable peer review reports (and hence have a higher estimated probability of getting a revise-and-resubmit) tend to go on to get more citations. So this is not all down to the effect of peer review reports on getting into the journal.
The paper also develops a statistical model of this whole process, leveraging the fact that we have a bit of quasi-experimental variation in which editors receive which papers. Basically, a paper assigned to a more lenient editor might get published and a similar paper assigned to a more stringent editor might not. That can help us measure the effect of getting published on citations; they find this effect to be quite small, relative to the trends highlighted in the figures above.
So this is good news: the potential value of a paper, as proxied by peer review, seem to be correlated with long-run citation counts, at least in economics.
But Card and DellaVigna also highlight some other confounding factors. Perhaps most seriously, they show that there is a systematic discrepancy between the citations received by more prominent authors (those who have published more in the past) and their peer review reports. In essence, prominent authors get more citations than their peer review reports would otherwise imply they “should” get. Maybe author prominence is one of the factors that affects initial citations, regardless of research quality, and then this effect is amplified through the channels discussed previously? To dig a bit more into this result, the authors conducted a small follow-up survey (74 responses from faculty and PhD students) to see if other economists thought the citations received by prominent authors were less deserved than those accruing to less prominent ones. But they actually find little evidence of this.
What’s going on here? We don’t fully know. Card and DellaVigna think maybe editors and referees are grading submissions by more prominent authors more harshly, possibly because these journals are secure in their academic position and want to help new (non-prominent) people into the field, or possibly because they fear prolific authors won’t cooperate as much with requested revisions. If that’s the case, the stated referee recommendation understates the true contribution of the submission, and later citations pick this up. Another possibility is that reviewers do not actually treat the papers of prolific authors differently, so that the stated recommendation accurately reflects the potential value of a paper, but prolific authors are more likely to be discovered by readers, and hence cited. The subtle twist here is the survey evidence suggests these citations are not undeserved, so if prominence leads to more citations, we would need to believe this is because prominence serves like a focal point for organizing future research: the extra citations reflect genuine influence and not mere rhetorical armor.
Good, but Far From Great
For the purposes of doing research on research, it’s reassuring to see citation counts are correlated with other metrics of impact, whether those be scientist self-reports, text influence, non-academic citation, or peer review reports. But the correlation is not super tight. Most academic citations do not, in fact, represent major influence, according to surveys. The correlation between text influence measures and citation counts is on the order of 0.2-0.4, which is pretty modest. It’s probably true that highly cited papers - the top couple percent - really are much more impactful than the median paper. But getting much more specific than that is challenging unless you have a lot of data so the signal can shine through the noise.
And that’s just a measure of whether a paper has impact. There is a whole different question of whether that impact is strongly correlated with the potential value of a knowledge contribution. It’s quite likely that citations are partially driven by a feedback loop that can amplify random bits of good and bad luck, as well as different forms of bias. The underlying quality of a paper is certainly in the mix, but so are a lot of other things.
The glass half-full read on this is that there is a lot of room left to improve our measures of science. We don’t have to be satisfied that this is the best its going to get. There is a growing body of work2 attempting to use new natural language processing techniques to improve citation metrics, for example by looking at how the text surrounding a citation references it. Text similarity and influence measures are also in early days, in terms of their use for studying science. And more and more of the academic record is currently being digitized; maybe we will find that citations from course syllabi and textbooks (or wikipedia?) are even better measures of influence than citations in papers? Finally, perhaps we will eventually be able to combine all these ingredients - citations, plus their context on the page, and the similarity of the text between citing and cited articles, and linkages to more of the non-paper corpus - into something better than any individual metric.
As always, if you want to chat about this post or innovation in generally, let’s grab a virtual coffee. Send me an email at mattclancy at hey dot com and we’ll put something in the calendar.
New Things Under the Sun is produced in partnership with the Institute for Progress, a Washington, DC-based think tank. You can learn more about their work by visiting their website.
In practice, we will probably want to adjust for time and field specific factors, but that’s not hard.
See Tahamtan and Bornmann (2019) for one recent overview