


Like the rest of New Things Under the Sun, this article will be updated as the state of the academic literature evolves; you can read the latest version here.
You can listen to this post above, or via most podcast apps here.
Note: Have an idea for a research project about how to improve our scientific institutions? Consider applying for a grant of up to $10,000 from the Metascience Challenge on experiment.com, led by Paul Niehaus, Caleb Watney, and Heidi Williams. From their call for proposals:
We're open to a broad set of proposals to improve science -- for example, experimental designs, surveys, qualitative interviews with scientists, pilot programs for new mechanisms, scientific talent development strategies, and other research outputs that may be relevant for scientific research funders.
The deadline to apply is April 30. On to our regularly scheduled programming!
Scientific peer review is widely used as a way to distribute scarce resources in academic science, whether those are scarce research dollars or scarce journal pages.1 Peer review is, on average, predictive of the eventual scientific impactof research proposals and journal articles, though not super strongly. In some sense, that’s quite unsurprising; most of our measures of scientific impact are, to some degree, about how the scientific community perceives the merit of your work: do they want to let it into a journal? Do they want to cite it? It’s not surprising that polling a few people from a given community is mildly predictive of that community’s views.
At the same time, peer review has several potential short-comings:
Multiple people reading and commenting on the same document costs more than having just one person do it
Current peer review practices provides little incentives to do a great job at peer review
Peer review may lead to biases against riskier proposals
One alternative is to empower individuals to make decisions about how to allocate scientific resources. Indeed, we do this with journal editors and grant makers, though generally in consultation with peer review. Under what conditions might we expect individuals empowered to exercise independent judgement to outperform peer review?
To begin, while peer review does seem to add value, it doesn’t seem to add a ton of value; at the NIH, top-scoring proposals aren’t that much better than average, in terms of their eventual probability of leading to a hit (see this for more discussion). Maybe individuals selected for their scientific taste can do better, in the same way some people seem to have an unusual knack for forecasting.
Second, peer reviewers are only really accountable for their recommendations insofar as it affects their professional reputations. And often they are anonymous, except to a journal editor or program manager. That doesn’t lead to strong incentives to try and really pin down the likely scientific contribution of a proposal or article. To the extent it is possible to make better judgments by exerting more effort, we might expect better decision-making from people who have more of their professional reputation on the line, such as editors and grant-makers.
Third, the very process of peer review may lead to risk aversion. Individual judgment, relying on a different process, may be able to avoid these pitfalls, at least if taking risks is aligned with professional incentives. Alternatively, it could be that a tolerance for risk is a rare trait in individuals, so that most peer reviewers are risk averse. If so, a grant-maker or journal that wants to encourage risk could do so by seeking out (rare) risk-loving individuals, and putting them in decision-making roles.
Lastly, another feature of peer review is that most proposals or papers are evaluated independently of each other. But it may make sense for a grant-maker or journal to adopt a broader, portfolio-based strategy for selecting science, sometimes elevating projects with lower scores if they fit into a broader strategy. For example, maybe a grant-maker would want to support in parallel a variety of distinct approaches to a problem, to maximize the chances at least one will succeed. Or maybe they will want to fund mutually synergistic scientific projects.
We have a bit of evidence that empowered individual decision-makers can indeed offer some of these advantages (often in consultation with peer review).
Picking Winners Before Research
To start, Wagner and Alexander (2013) is an evaluation of the NSF’s Small Grants for Exploratory Research programme. This program, which ran from 1990-2006, allowed NSF programme managers to bypass peer review and award small short-term grants (up to $200,000 over 2 years).2 Proposals were short (just a few pages), made in consultation with the programme manager (but not other external review), and processed fast. The idea was to provide a way for programme managers to fund risky and speculative projects that might not have made it through normal peer review. Over its 16 years, the SGER (or “sugar”) program disbursed $284mn via nearly 5,000 awards.
Wagner and Alexander argue the SGER program was a big success. By the time of their study, about two thirds of SGER recipients had used their results to apply for larger grant funding from the conventional NSF programs, and of those that applied 80% were successful (at least, among those who had received a decision). They also specifically identify a number of “spectacular” successes, where SGER providing seed funding for highly transformative research (judged as such from a survey of SGER awardees and programme managers, coupled with citation analysis).
Indeed, Wagner and Alexander’s main critique of the programme is that it was insufficiently used. Up to 5% of agency funds could be allocated to the program, but a 2001 study found only 0.6% of the budget actually was. Wagner and Alexander also argue that, by their criteria, around 10% of funded projects were associated with transformational research, whereas a 2007 report by the NSF suggests research should be transformational about 3% of the time. That suggests perhaps program managers were not taking enough risks with the program. Moreover, in a survey of awardees, 25% said an ‘extremely important’ reason for pursuing an SGER grant was that their proposed research idea would be seen as either too high-risk, too novel, too controversial, or too opposed to the status quo for a peer review panel. That’s a large fraction, but it’s not a majority (the paper doesn’t report the share who rate these factors as important but not extremely important though). Again, maybe the high-risk programme is not taking enough risks!
In general though, the SGER programme’s experience seems to support the idea that individual decision-makers can do a decent job supporting less conventional research.
Goldstein and Kearney (2018) is another look at how well discretion compares to peer review, this time in the context of the Advanced Research Projects Agency - Energy (ARPA-E). ARPA-E does not function like a traditional scientific grant-maker, where most of the money is handed out to scientists who independently propose projects for broadly defined research priorities. Instead, ARPA-E is composed of program managers who are goal oriented, seeking to fund research projects in the service of overcoming specific technological challenges. Proposals are solicited and scored by peer reviewers along several criteria, on a five-point scale. But program managers are very autonomous and do not simply defer to peer review; instead, they decide what to fund in terms of how proposals fit into their overall vision. Indeed, in interviews conducted by Goldstein and Kearney, program managers report that they explicitly think of their funded proposals as constituting a portfolio, and will often fund diverse projects (to better insure at least one approach succeeds), rather than merely the highest scoring proposals.
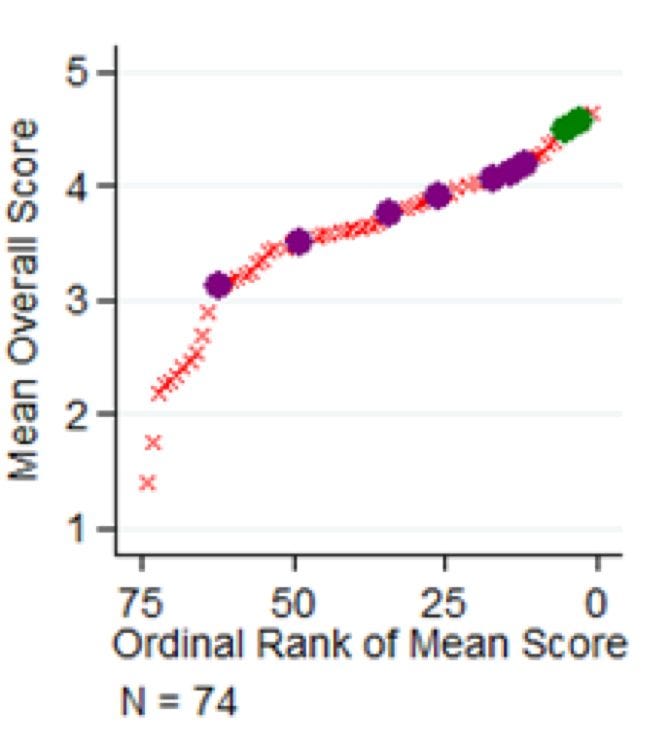
Goldstein and Kearney have data on 1,216 proposals made up through the end of 2015. They want to see what kinds of projects program managers select, and in particular, how they use their peer review feedback. Overall, they find proposals with higher average peer review scores are more likely to get funded, but the effects are pretty weak, explaining about 13% of the variation in what gets funded. The figure above shows the average peer review scores for 74 different proposals to the “Batteries for Electrical Energy Storage in Transportation” program: filled in circles were funded. As you can see, program managers picked many projects outside the top.
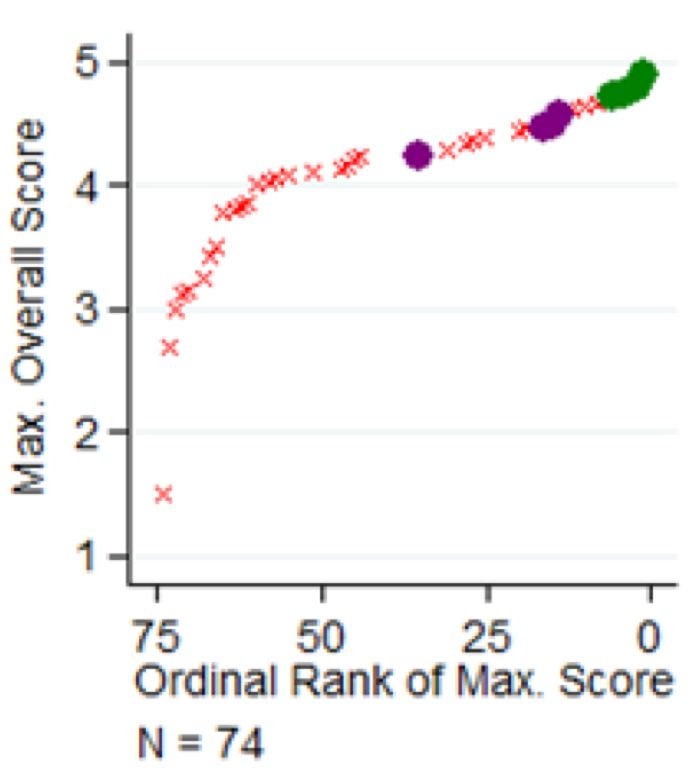
What do ARPA-E program managers look at, besides the average peer review score? Goldstein and Kearney argue that they are very open to proposals with highly divergent scores, so long as at least one of the peer review reports is very good. Above, we have the same proposals to the Batteries program listed above, but instead of ordering them by their average peer review score, now we’re ordering them by their maximum peer review score. Now we’re seeing more proposals getting funded that are clustered around the highest score. This is true beyond the battery program: across all 1,216 project proposals, for a given average score, the probability of being funded is higher if the proposal receives a wider range of peer review scores. Goldstein and Kearney also find proposals are more likely to be funded if they are described as “creative” by peer reviewers, even after taking into account the average peer review score.
ARPA-E was first funded in 2009, and this study took place in 2018, using proposals made up through 2015. So there hasn’t been a ton of time to assess how well the program has worked. But Goldstein and Kearney do an initial analysis to see how well projects turn out when program managers use their discretion to override peer review. To do this, they divide the 165 different funded proposals into two groups: those with average peer review scores high enough to ensure they would have been funded, if the program managers completely deferred to peer review, and those that were funded in spite of lower average peer review scores. They find, in general, no evidence that the proposals where the program manager overrode peer review are any less likely to result in a journal publication, patent, or market engagement (which is tracked by ARPA-E). This is notable, given that, as noted above, higher peer review scores are usually correlated with things like more publications or patents. At the same time though, those studies find the correlation between peer review scores and eventual impact is pretty noisy, and might be hard to detect with just 165 observations.
Picking Winners After Research
We also have some studies on how journal editors mix peer review with their own discretion when deciding which papers to publish. Card and Dellavigna (2020) have data on nearly 30,000 submissions to four top economics journals, as well as the recommendations of the peer review reports. Because, in economics, it is quite common for draft versions of papers to be posted in advance of publication, Card and Dellavigna can see what happens to papers that are accepted or rejected from these journals, including how many citations they go on to receive (both as drafts and published versions).
One thing we can do with this data is see if empowered decision-makers - in this case editors - can improve on peer review. One way we can test that is to compare the fates of submissions that get similar peer review scores, but where one of the papers was rejected by the editor and the other allowed to proceed through the revise-and-resubmit process. We can then see how the citations ultimately received by these submissions varies. If peer review can’t be improved on, then we shouldn’t expect there to be much of a difference in citations between the articles the editor rejects and the ones they allow to proceed. But if the editor has some ability to spot high impact research, above and beyond what’s in the peer review reports, then we should expect the submissions receiving a revise-and-resubmit to outperform the papers rejected.
In the figure below, we can see how this plays out. On the horizontal axis, we have the estimated probability that a submission with a given set of peer review scores (plus information on the number of authors and the publication track record of the author) receives a revise-and-resubmit, and on the vertical axis we have a measure of citations (in modified log form, so that each interval represents an order of magnitude). All the lines slope up, meaning the higher the peer review scores, the higher the citations the submission goes on to receive.
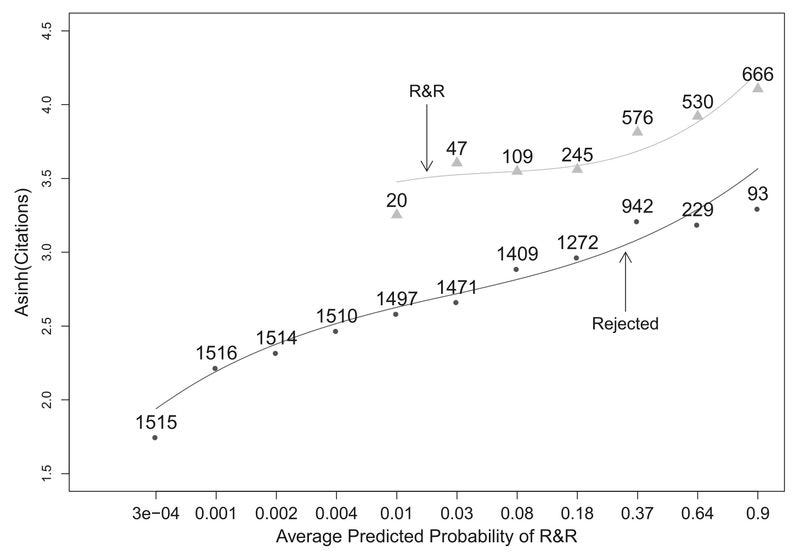
What’s interesting for us today is the gap between the two lines. On the top, we have the citations received by papers the editor sent out for a revise-and-resubmit; on the bottom, the citations received by the papers the editor did not. There’s a pretty big gap between the two. Among submissions with very similar peer review scores, those the editor thought merited a revise-and-resubmit, tend to receive a lot more citations than those who they did not. At least for these journals, which try to identify high-impact research, the editors seem to have the ability to spot something peer reviewers missed.
That all said; an alternative interpretation is that this has nothing to do with editor taste, and instead everything to do with the citation bump you get from being published in a top journal, which is more likely if the editor sends your submission out for a revise-and-resubmit. The paper is pretty worried about this and spends a lot of energy trying to model this effect, by using the differing levels of stringency among randomly assigned editors as a natural experiment in the effects of being published. Some people are randomly assigned to a lenient editor, others to a stringent one, and they treat that as an experiment in the effect of getting published. They find the extra citations that can be attributed purely to being published in a top journal are pretty small, no more than half the effect seen in the figure, and likely much less. They also find the papers editors desk-reject also get fewer citations than those sent out for peer review, but still rejected. That’s another line of evidence that editors have the ability to sniff out more and less promising work that avoids the distortions caused by getting published in these journals, though in this case we can’t compare their performance to peer review (since desk-rejected papers get no peer review reports).
Finally, another paper that lets us compare peer review and editor decision-making is Teplitskiy et al. (2022), which has data on thousands of submissions to Cell, Cell Reports, and the journals of the Institute of Physics Publishing, dating to between 2013 and 2018. Teplitskiy and coauthors are more interested in how novelty is judged by journals, rather than the number of citations ultimately received by papers.
To measure novelty, they use a common measure based on the citations an article makes. For every pair of journals cited by the submission, they create a measure of how atypical it is for these journals to be cited together, based on the frequency they have been cited together in the past (relative to what you would expect due to random chance). They then order these pairings from least to most typical, and use the atypical score at the tenth percentile as their measure of how novel a paper is. Basically, this measure zooms in on the most surprising combinations of journals cited, and uses those as a proxy for how novel the overall article is. A submission whose most unusual combination of cited references is Cell and Cell Reports is probably not very novel; a submission that cites both Cell and the Journal of Economic History may be.
In one analysis, Tepliskiy and coauthors break the publication pipeline into three steps: the decision to send out for review (rather than desk reject), the peer review recommendation (reject or suggest revisions/accept), and the ultimate decision to publish. At each of these stages, they look to see how novelty of the submission affects its progression through the publication pipeline, where submissions get more novel as we move from the first to fifth quintile.

On the far left, we have the decision made by an editor to send a submission out for peer review. Across all journals, the most novel submissions (those citing the most unusual set of references) are more likely to be sent out for peer review. In the middle panel, we have the recommendation of the peer reviewers to reject or issues a revise-and-resubmit (or just outright accept the publication). Here the effect varies; in Cell peer reviewers are basically indifferent to novelty (as defined in this paper), while at the Institute of Physics, peer reviewers continue to prefer the most novel papers. Teplitksiy and coauthors don’t have peer review data on Cell Reports, so it is omitted from the figure. Finally, on the right panel, we have the editor’s decision to accept the publication. In this panel, we’re seeing how the impact of novelty, holding fixed the peer review recommendations. Again, the results vary, but now in the other direction. At Cell, among submissions with similar peer review recommendations, journal editors are much more likely to accept papers that are more novel. At the Institute of Physics, novelty doesn’t seem to matter after the peer review stage.
All in all, Cell seems to demonstrate how an editor with a taste for novelty can boost the prospects of novel research, relative to (in this case), indifferent peer reviewers. But at best, this is an existence proof; we don’t really see the same dynamics in the other set of journals, so we can’t say this is a general result.
We Need to Know More
To sum up, at the NSF, a program that allows managers to use their discretion to bypass peer review and fund riskier research seems to have worked pretty well, though it was perhaps underused and we don’t have a clean study setting where we can compare the program to a more conventional one. At ARPA-E, we can see that program managers regularly pass on proposals with high average peer review, perhaps in favor of proposals that are creative or have at least one enthusiast, and which perhaps better satisfy needs of the research portfolio. At present, we don’t see that they face any penalty for taking this approach. Meanwhile, on the journal side, we have some evidence in economics that editors have some skill at selecting higher impact research from papers with similar peer review scores, and in one major biology journal that editors seem to use their discretion to select more novel research (though we don’t see this in another set of journals).
The main thing I take away from all this is that the individuals who we empower to make the ultimate decisions about the allocation of scientific resources could matter a lot. At the same time, I don’t think we know much about them, compared, for example, to what we know about the individuals who allocate resources in the rest of the economy; bankers, traders, venture capitalists, etc.3 What are the incentives faced by our allocators of scientific resources? How are they selected? What kind of feedback do they get on their performance? Would such feedback matter? Do successful allocators share certain traits, whether those are in terms of their personality or professional background? How well are they at forecasting?
Lots we could learn.
Thanks for reading! As always, if you want to chat about this post or innovation in generally, let’s grab a virtual coffee. Send me an email at matt.clancy@openphilanthropy.org and we’ll put something in the calendar.
In the digital age, pages themselves are not really scarce, but reader attention may still be.
In 2007 it was replaced by the EAGER and RAPID programmes, which have a similar setup. EAGER is designed to fund exploratory research, RAPID is designed to be a fast grant for urgent priorities.
If you know of more relevant work on these issues, please send it my way!