

Innovation is hard because you have to step into the unknown and it’s never certain what you’ll find there. Most of the time, nothing useful. We use knowledge - models, regularities, analogies from similar cases and so on - to reduce that uncertainty; but it’s always there.
When an individual or organization learns new knowledge, with a bit of luck the knowledge opens up new possibilities: it provides a map (more or less high resolution, depending on the state of things) of the unknown territory. So people whose business is innovation and discovery spend a lot of time searching for new and useful knowledge by reading, attending conferences, and talking with people. But the universe of knowledge is vast. Is there any rhyme or reason to searching through it? What kind of knowledge is most likely to be useful?
This is a big literature, but today I want to look at three papers that use different metrics to suggest knowledge which is distinct but close to your existing knowledge tends to be most useful.
To start, let’s look at a really clean experiment by Lane, Ganguli, Gaule, Guinan and Lakhani. Lane and coauthors ran an experiment back in 2011 where they invited all the life sciences faculty and researchers affiliated with a large US medical school to a symposium on medical research. As part of the symposium, participants were randomly assigned to different rooms, where they could look at research posters and talk with other researchers. Attendees were also fitted with a “sociometric badge” (see image below) that the authors used to determine who talked with whom: basically, if two badges were within 1 meter of each other and facing each other for one minute, the paper codes the attendees as having a face-to-face interaction.

Taken from the appendix of Kim et al. (2012)
Lane and coauthors also measure how “similar” each attendee’s knowledge is to their conversation partners. The primary measure they focus on uses the keywords attached to articles they’ve published. All these researchers are in the life sciences, which has a standardized vocabulary of descriptive keywords called the MeSH lexicon. They rate two people as having a low overlap if their published work has only two or fewer MeSH keywords in common, medium overlap if they have 3-11 words in common, and high overlap if they have 12 or more in common. They then keep track of these attendees for the next six years to see the long-run fallout from these accidental encounters with new knowledge (or, more precisely, with people whose brains have new knowledge).
So; we randomize people into different rooms; we see who they talk to; and we have very rough proxies for the kinds of things everyone knows. The first thing the authors show is that coauthorships are most likely to be born out of these conversations when researchers have an intermediate level of knowledge similarity. Perhaps surprisingly, people are slightly less likely to collaborate if they have a very high level of overlap and they meet each other at this conference.

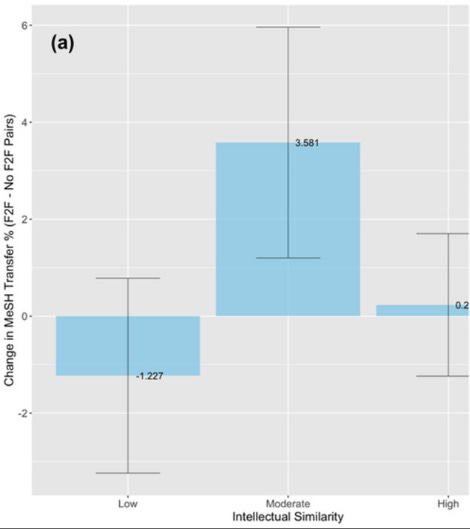
Of course, there are other ways knowledge can be useful besides collaboration. Lane and coauthors try to get at that in two ways. First, they look to see if people are more likely to cite each other’s work when they meet. Again - it’s that intermediate level of knowledge overlap that most benefits from the face-to-face encounter:

What about knowledge that you can’t directly trace back to a citation? To get at that, Lane and coauthors look at those MeSH keywords again. In the following six years, are you more likely to start working on topics that match the keywords of your conversation partner? It turns out that again the answer is yes - if your conversation partner has that intermediate distance in terms of knowledge similarity.
Pretty impressive that you can see anything at all from a 90 minute opportunity to mingle! That said, since all these researchers were affiliated with the same institution, it’s quite likely that they had the opportunity to expand on these initial encounters if they found them fruitful.
Now let’s look at a very different and non-experimental context: what kind of ideas are found useful by new agricultural technologies?
Clancy, Heisey, Ji, and Moschini (2020) (that’s me, buyer beware) identified slightly more than 50,000 US patents, granted between 1976-2016, for agricultural technologies (think veterinary medicine, GMO plants, fertilizer, pesticides, tractors, etc). We then tried to identify the sources of the ideas that the patented technologies built on. There are no perfect measures for this, so we went about it in a few different ways. In each case, we found it to be pretty common that the majority of “knowledge” originated outside of agriculture… but not too far outside agriculture. This will be clearer with some examples.
For example, we looked at the citations agricultural patents make to academic journal articles. We then sorted the cited academic journals into different categories: agricultural science, biology, chemistry, and everything else. Most of the time, patents cite journals that don’t belong to the agricultural science category. But they still mostly cite chemistry and biology journals, even though the “everything else” category is much larger. Knowledge “close” to agriculture just tended to be more useful, or at least that’s our interpretation.
We also tried to identify the sources of knowledge that were borrowed from other technologies, instead of academia. For example, we looked at the citations agricultural patents make to other patents. We also looked at the actual text of these agricultural patents. Specifically, for each agricultural sub-field we identified at least 100 phrases (1-3 words) that corresponded to new technological concepts. These were phrases which were absent from the agricultural patent record before 1996, but relatively common thereafter (we think of them as new and important concepts). One example is the word “pyrimethamine”, which became common in veterinary medicine patents after 1996 but was absent beforehand. We then looked to see if these phrases popped up in other non-agricultural patents before 1996. Most of the time, they did. That means agriculture wasn’t the first patent to use these phrases. For example, pyrimethamine was pretty common in patents for human medicine before it began to appear in veterinary medicine patents after 1996.
So what kind of patents produce knowledge that’s useful to agriculture? Most of the time it wasn’t other agricultural patents (with one important exception - patents for plants tend to heavily cite patents for plants and other agricultural research patents). Most of the time, non-agricultural patents were the ones we linked to agricultural patents, via citation or shared phrases. But still, even though this indicates agricultural patents are borrowing knowledge from non-agricultural patents, most of these non-agricultural patents belonged to firms that also already had agricultural patents. This is despite the fact that these firms are in the minority. That is, most of the borrowed ideas came from firms who already had some pre-existing connection to agriculture, even though it was not their main area of patenting.

Let’s look at one more example. Cornelius, Gokpinar, and Sting (2020) study a completely different context: temporary assignments of automobile workers to different factories. One thing that’s really nice about this paper is it has a completely distinct measure of innovation. For a large unnamed European auto manufacturer, employees are encouraged to submit ideas for improving the efficiency and quality of auto production. These ideas are submitted to a database where they are evaluated by accountants to see if they will save the company money if implemented. So this is the dataset Cornelius, Gokpinar, and Sting are working with - employee ideas with dollar values in savings attached! (It’s super rare to find a dataset that provides such a good measure of the “value” of an idea, even though ideas vary enormously in their value)
They then look to see what happens to the value of ideas submitted by employees after they visit another plant. Plants differ (more on this in a minute), so visiting another plant is a way to learn about different approaches for assembling auto parts. After a visit, the average estimated savings of an employee’s ideas increase by about $25,000 per idea basically forever (and several times as high in the short term). The notion here is that being exposed to new ways of doing things allows workers to think of new and better improvements.
The challenge a paper like this has to confront is that employees aren’t just randomly assigned to visit another plant. The kinds of employees that are sent out for a visit tend to be very good employees and they already generate more than the average number and value of ideas. So if we just compare the value of ideas for employees who have gone on trips to those that haven’t, we’ll get a biased result, since the people making visits probably would have had more valuable ideas whether they went on a trip or not.
The authors try to account for this in two ways: first, they look only at how site visits change the value of an individual’s ideas over time (comparing the same person’s ideas before and after a visit), and also taking into account typical trends in how idea values evolve over time (more experienced employees usually have better ideas). In econ jargon, they have individual fixed effects and time-varying measures of idea quality. Second, they compare employees who go on site visits to those who come from the same plant and are similar in terms of their ability to generate valuable ideas, but where one is assigned to visit and the other is not. Both methods deliver the above result: visits increase the value of subsequent ideas.
But not all site visits are alike. Some plants have significantly more overlap in terms of the products produced and the machinery used than others. The authors find it’s visits to these similar plants that generate by far the most value.
Bottom line: learning something new by visiting a new plant increases the value of subsequent ideas for an employee; but that impact falls off if the plant is too different from the one the employee normally works at.
So, in these three cases - producing papers in the life sciences, descriptive work on the sources of ideas in agricultural technology patents, and submitted ideas for improving the efficiency of automobile manufacturing - it looks like inventors find most useful knowledge that is not exactly where they already are, but adjacent.
This isn’t the last word though. This is a big literature and we’ll be back here sometime again.





