


Progress in Programming as Evolution
Do the same mechanisms that create complex life also create complex technology?
Like the rest of New Things Under the Sun, this article will be updated as the state of the academic literature evolves; you can read the latest version here.
Audio versions of this and other posts: Substack, Apple, Spotify, Google, Amazon, Stitcher.
Evolution via natural selection is a really good explanation for how we gradually got successively more complex biological organisms. Perhaps unsurprisingly, there have long been efforts to apply the same general mechanism to the development of ever more complex technologies. One domain where this has been studied a bit is in computer programming. Let’s take a look at that literature to see how well the framework of biological evolution maps to (one form of) technological progress.
Simulating Technological Evolution
We’ll start with Arthur and Polak (2006), who look at how ever more sophisticated logic circuits can, in principle, evolve via a blind process process of mutation, selection, and recombination. The paper reports the results of a large number of digital simulations that do precisely that. These simulations have three main components.
First if you’re going to simulate evolution, you need your organism, or in this case, your technology. Arthur and Polak start with a very elementary logic gate, in most simulations a Not-And (NAND) gate. This is a circuit with two binary inputs and one binary output. If every input is 1, then it spits out 0; otherwise it spits out 1. From this seed, much more sophisticated circuits will digitally evolve.

The second thing you need in order to simulate evolution is a way to modify the organism or technology. We might think the natural way to do this is to allow for slight mutations in these circuits, which is how we often think of biological evolution (single base-pairs being switched from one to another). But Arthur and Polak believe recombination is the essence of technological change, rather than mutation. So their model of digital evolution is much more explicitly combinatorial. In every period, sets of 2-12 technologies are picked and randomly wired together in sequence, though any individual circuit is also allowed to mutate a bit on its own.
Third, to model evolution you need a way to evaluate the fitness of your organisms, or circuits in this case. If we’re trying to understand technological evolution, then fitness should be related to whether or not humans find technologies to be useful. Arthur and Polak come up with a list of desired functions it is reasonable for people to want circuits to fulfill. These range from very simple to very complex. For example, one simple function is just a NOT gate: it just returns the opposite of its input (1 for 0, 0 for 1). A more complex function is a 15-bit adder: if you put in two 15-bit numbers, it outputs their sum.
Arthur and Polak next come up with a way to score circuits based on how close they get to giving the right answer: every time the circuit gives the right answer for a set of inputs, it scores better, every time it gives the wrong answer, it scores worse. And if two circuits perform equally well, the one that does it with fewer components scores better. In every period, the highest scoring circuits and their components gets retained. Next period, the simulation draws components from this basket of retained circuits and wires them together to see if any of the resulting combinations do a better job fulfilling the desired tasks.
Finally, Arthur and Polak let this system run for 250,000 periods, 20 different times, and watch what happens. We learn a few things from the results of this exercise.
First, the experiment is an existence proof that you don’t need inventors with reasoning minds to get sophisticated technologies; this blind recombinant evolution can also do the job. In 250,000 period these simulations don’t discover everything Arthur and Polak define as desirable, but it does go well beyond the simplest circuits. For example, the simulation successfully discovered circuits that can add 4-bit numbers and and circuits that can indicate if one (and only one) of 8 inputs is 1.
Second, in the experiment, technological advance tends to be lumpy. Desirable circuits tend to be discovered in clusters, after key component pieces are discovered which unlock lots of new functionality. But in between these sprints can be long periods of technological stagnation, even as under the surface the ferment of experimentation and “R&D” is going on invisible to us.
Third, their simulations give a nuanced picture about the importance of path dependency. This is the idea that where our technologies start has a big impact on where they finish. If we start along one technological trajectory, we’re more likely to continue on it, and end up with a completely different basket of technologies, than if we started elsewhere. In Arthur and Polak’s experiments, one way they can investigate this is to see how different simulations evolve, when different circuits are discovered first. For example, most of the time, a “not” circuit is found before an “imply” circuit. But not always. In the rarer cases when “imply” circuits are found first, many subsequent technologies build on the imply circuit than the “not” circuit. Over time, however, the program still sniffs out the best overall approaches for different functions, and this begins to chip away at the initially atypical dominance of “imply” components. The importance of where you start matters for a time, but then begins to fade.
Fourth, technological innovation, like biological innovation, is red in tooth and claw. Better technologies constantly supplant obsolete ones and sometimes this leads to waves of extinction. For example, suppose some technology x is comprised of 12 other circuits, and each of these component circuits is further comprised of 2-12 subcomponents, which are in turn comprised of sub-subcomponents and so on. If technology x is replaced by a superior technology y, then technology x naturally goes “extinct.” And if the components and subcomponents, and sub-subcomponents that comprised x are not part of any other technology that is the highest scoring on some function (and therefore retained), than they too can go extinct, leading to the collapse of an entire ecosystem of supportive circuits.
Lastly, Arthur and Polak’s digital experiment illustrates the importance of intermediate goals in the evolution of technological complexity. In their simulations, if Arthur and Polak remove key desirable circuits of intermediate complexity, the simulations get trapped and unable to advance to more complex designs. Evolution needs stepping stones to get from simple to complex.
Evolution in MatLab Contests
This is an intriguing experiment, but it’s doesn’t demonstrate that these mechanisms are important in the actual development of technology. For that, I am a big fan of two papers from 2018 and 2020 by Elena Miu, Ned Gully, Kevin Laland, and Luke Rendell. These papers study 19 online programming competitions operated by MathWorks over 1998-2012. This is still an artificial setting, but we now have real people solving real programming problems, and as we’ll see, these contests have some important elements that make them worth studying.
In these contests, nearly 2000 participants (average of 136 per contest) competed over the course of a week to write programs in MATLAB that could find the best solution to a problem in which it was impossible to find an exact solution in the time given. For example, in a 2007 contest participants wrote code to play a kind of peg-jumping game, where there is a grid of pegs (all worth different points) and an empty space, and you can remove a peg by jumping over one peg and into an empty space. A program’s score was based on three factors: the number of points it got in the game; how fast it ran, and how complex the code is (with more complex code penalized).
Participants could submit their programs at any time and receive a score. They could then modify their code in response to the score they received, and this iterative improvement was an important part of the contest. But there is a catch: programs and their scores were publicly viewable by all participants. So submitting a program and getting feedback on its performance also discloses your program to all the other contest participants, who are free to borrow/steal your ideas.
This is a great setting to study technological evolution, for a few reasons. As in the real world, there is robust competition, and inventions can be reverse-engineered and copied. Unlike Arthur and Polak, we have reasoning minds designing and improving programs, rather than blind processes of recombination and selection. But perhaps most importantly, for the purposes of studying technological evolution, we can see the complete “genotype” of computer programs by reading their code. And with standard text-analysis packages, Miu and coauthors can see exactly which lines and blocks of code are copied and how similar programs are to each other. Lastly, because programs are explicitly scored (and players care about these scores; they are actively seeking the highest score), Miu and coauthors also know exactly how “good” a program is.
The figure below tracks how scores improve for a sample of 4 contests. In the figure, each dot is a program. The horizontal axis is time (each contest runs 7 days) and the vertical is the score (lower is better). Clearly the best programs improve over time, in fits and starts.

When Miu and coauthors peer into the underlying dynamics, in their 2018 paper they see that the most common type of program that is submitted is a program that is very similar to the current leader, but with minor tweaks. In their 2020 follow-up, they also document that when two programs have the same score, people are more likely to copy the one submitted by the participant who tends to score higher in their other submitted programs (even if those are in other contests). In other words, they find a classic evolutionary dynamic, where the best organisms - here programs - have the most “offspring” and each of these offspring is a slight variant on the “fittest organism.”
As in Arthur and Polak, this tweaking has a recombinant character; in only 25% of cases were new programs merely a refinement of a single existing program. More often, changes were copied from other programs; the average submission stitched together code from 2.8 different programs. Over time, this means programs come to incorporate code snippets from tens or hundreds of different sources.
But tweak are not the whole story. There are also programs that diverge substantially from what has come before. These evolutionary “leaps” were most often flops, but when they succeeded, they tended to succeed big. In other words, tweaking the current best code was more likely to lead to a small incremental gain, while making a leap was more likely to a big gain or, more often, a big fail.
But this only last so long. After the first 1-2 days of the seven day contest, it becomes rare that an innovation that is very dissimilar to the current leader becomes the new leader. More generally, Miu et al. (2018) show that as copying becomes the dominant strategy, the diversity of programs declines over time, where diversity is a measure of how different two programs typically are from each other. As with Arthur and Polak, this seems to suggest path dependence; once a general approach to programming a solution becomes dominant, iterative refinement of this approach means it gets increasingly hard for alternative approaches to get on the leaderboard and then benefit from iterative refinement of their own.
From Simulation to Reality
These papers demonstrate evolutionary dynamics in simulation and in certain artificial settings. But do these dynamics matter out in the “real world”, where programs are not just meant to solve fake problems but to instead facilitate a huge number of real world computational tasks? While we can’t observe these dynamics in nearly such rich detail, Valverde and Solé (2015) is an attempt to apply an evolutionary lens to the actual history of computer programming languages.
Valverde and Solé want to derive an evolutionary tree for 347 different programming languages invented between 1952 and 2010. Such a tree would show how every programming language splits off from some unique ancestor. That’s actually a bit of an uncomfortable metaphor for technological evolution though; the previous papers suggest each programming language might borrow from lots of ancestors.
And Valverde and Solé do find something like this. For every programming language, they look to see which other programming languages are cited as influences, using that language’s wikipedia article as their data source. Indeed, most do cite multiple languages, as can be seen from the following network of linkages between programming languages.

But it remains instructive to try and identify the single most influential programming language from among all the ancestor languages that influenced a new programming language. They can do this through an algorithmic approach (if interested in the details of how it works, check out the extra credit section at the bottom of this article). Once Valverde and Solé have identified each programming language’s most influential ancestor, an evolutionary tree can be built, though we should interpret it as being more like a map of which languages are highly influential, rather than a map of ancestry in the biological sense. The trees Valverde and Solé come up with are below:
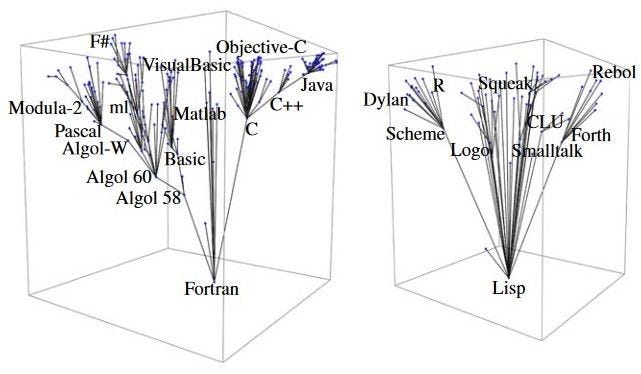
What do we learn from this exercise? I see at least two themes.
First, as with Arthur and Polak, innovation is lumpy. A few key programing languages lead to “speciation events”, possibly because they provided key conceptual components to unlock a lot of other useful features. Second, once again see a kind of path dependency; languages are divided into two separate trees, one (left above) corresponding to the imperative/procedural programming families, the other to the declarative programming families (which include the function and logical programming subgroups). The kinds of languages that start out influence the kind of languages you end up with. That said, recall that these trees track only ancestry along the most influential direction; when we include less influential links, these trees are not fully separated. In other words, a language in the right tree above might be mostinfluenced by Lisp, while still being somewhat influenced by languages derived from Fortran.
Technological Progress as Extended Evolution?
So is the same process that built complex organisms also broadly responsible for complex technology? At least for computer programs, I think an unusually recombinant form of evolution is almost certainly part of the story.
And I would be surprised if similar dynamics don’t play out in many other technological domains. The most immediate thing that comes to my mind is the stylized fact that the number of citations a patent receives from other patents tends to be a reliable signal of how valuable that patent is, measured in various alternative ways. One mechanism that can generate that result is if the most valuable patents attract the most copying with modification, just as was the case for MatLab computer programs in Miu et al (2018). If these patent “tweaks” all cite the original patent, then that would tend to generate a correlation between how valuable the patented invention is and how many citations it receives.
Other domains have traditionally been harder to study, because you can’t read the “genotype” as easily as you can for computer code. But with increasingly sophisticated natural language processing techniques, maybe we’ll see more efforts to study “evolution” in other textual manifestations of technology, such as patents and product descriptions.
Thanks for reading! For other related articles by me, follow the links listed at the bottom of the article’s page on New Things Under the Sun (.com). And to keep up with what’s new on the site, of course subscribe!
Extra Credit
How did Valverde and Solé identify the most influential ancestor programming language, for each language? They borrow a technique from Gauldi, Yeung, and Zhang (2011) that works for any directed network. The basic idea can be explained with a metaphor.
Suppose during a career, you have two different mentors. Alice is an academic, Lana a lawyer. We want to identify the more influential mentor, but for some reason we can’t just ask you. More of Alice’s proteges go on to have an academic career and more of Lana’s proteges go into law, so if we could observe which field you went into, that would be another way to see who was more influential (in a sense). But suppose we can’t observe anyone’s career choices either. In fact, all we can observe is the network of proteges and mentors. We know who Alice mentored and who Lana mentored, and for all these proteges, we know who they mentored, as well as mentors they had other than Alice and Lana. Is there still a way to see whether Alice or Lana was more influential to you?
Well, suppose Alice was a more influential mentor to you, and so you went into academia. Once you embark on an academic career, you will probably seek out other academic mentors. And if you succeed and start mentoring people yourself, the people you mentor are also likely to be interested in academia. We’ll observe all these mentorships in our data. The key idea then is to see if you have more mentors and proteges in common with the other proteges of Alice the Academic, than with Lana the lawyer. Alice’s other proteges are more likely to be in academia and then to mentor and be mentored by academics. In contrast, Lana’s proteges are more likely to go into law and enter a completely different network of mentor and protege networks. Just so, for every programming language, Valverde and Solé identify the most influential ancestor by finding the one with whom there is the most in common among their descendants.
Humberto Maturana and Francisco Varela’s book, “The Tree of Knowledge: The Biological Roots of Human Understanding” is a book i think is of the most important ever written. It pretty much describes how everything is a cog in a larger system- from cells, to bodies, to societies, to ideologies, to thoughts, and even language. Fascinating book. It's been years so im a bit fuzzy on the details but i think it's definitely worth everyones time to read.