
April 2022 Updates
Combinations and Covid-19
New Things Under the Sun is a living literature review; as the state of the academic literature evolves, so do we. This post highlights two recent updates. One of those updates was pretty big, so I will end up copying the entire updated post below, rather than an excerpt. But first, one announcement and one shorter update.
Endless Frontier Fellowship
First, I wanted to do a quick plug for a new fellowship that’s probably of interest to some readers of this newsletter. It’s a one-year science and tech policy fellowship for talented early career individuals, called the Endless Frontier Fellowship. Fellows spend an immersive year embedded as policy entrepreneurs at EFF’s anchor organizations, the Institute for Progress (New Things Under the Sun’s partner), the Federation of American Scientists, or the Lincoln Network. It’s paid! If you want to apply, the deadline is May 2. More details here.
Covid-19 and Innovation
Second, the article Medicine and the Limits of Market Driven Innovation has been updated with some discussion of a new paper by Agarwal and Gaule (2022), which describes how the biomedical R&D machine responded to covid-19. It’s a bit hard to excerpt the updates, but two points emphasized are:
Agarwal and Gaule provide some additional evidence which confirms work done by other papers using earlier data. Biomedical R&D is responsive to the size of the profit opportunity associated with diseases: they find a 10% increase in the size of the market for a drug is associated with about 4% more clinical trials.
Against this benchmark, the response of biomedical R&D to covid-19 was a huge outlier. According to their estimates, the size of the “market” for a covid-19 treatment (based on global mortality from the disease) was bigger than the market for any other disease they considered. Even so the number of new clinical trials was 7-20 times larger than their model would have predicted.
Covid-19 was strange in other ways as well. One of the main arguments of Medicine and the Limits of Market Driven Innovation is that private biomedical R&D generally responds to profit opportunity only with projects that do not require much fundamental research. While we have pretty good evidence that this is the case, covid-19 represents a big counter-example. As discussed a bit in the new update, covid-19 did in fact lead to a major shift in the kind of research done throughout science (discussed in more detail here).
Data on Combinatorial Innovation
Lastly, I’ve written a fairly large update to a post originally called “Innovation as Combination: Data.” That was the fifth New Things Under the Sun I ever wrote, and it wasn’t quite in the style of today’s posts. I now try to make each piece make a specific claim, drawing on a set of related papers, but that piece was more a round up of some related articles. I’ve rewritten it to make a specific claim, which is encapsulated in the new title: “The best new ideas combine disparate old ideas.” It’s about 50% new material, with the set of articles covered going from 4 to 7. Rather than excerpt so much, I reproduce the whole updated post below; enjoy!
The Best New Ideas Combine Disparate Old Ideas
Where do new ideas and technologies come from? One school of thought says they are born from novel combinations of pre-existing ideas. To some extent that’s true by assumption, since everything can be decomposed into a collection of parts. But this school of thought makes stronger claims. One such claim is that new combinations - those pulling together disparate ideas - should be particularly important in the history of ideas.
And it turns out we have some pretty good evidence of that, at least from the realms of patents and academic papers (and also computer programming). To get at the notion that new ideas are combinations of older ideas, these papers all need some kind of proxy for the pre-existing ideas that are out there, waiting to be stitched together. They all ultimately rely on classification systems that either put papers in different journals, or assign patents to different technology categories. These journals or technology classifications are then used as stand-ins for different ideas that can be combined. A paper that cites articles from a monetary policy journal and an international trade journal would be assumed to be combining ideas from these disciplines then. Or a patent classified as both a “rocket” and “monorail” technology would be assumed to combine both ideas into a new package technology.
New Combinations in Patents and Citations
A classic paper here is Fleming (2001), which uses highly specific patent subclasses to proxy for combining technologies. There were more than 100,000 technology subclasses at the time of the paper’s analysis, each corresponding to a relatively narrow technological concept. Using a sample of ~17,000 patents granted in May and June 1990 Fleming calculates the number of prior patents assigned the exact same set of subclasses. He shows patents assigned combinations without much precedent tend to receive more citations, which suggests patents that combined rarely combined concepts were indeed more important. For example, as we go from a patent assigned a completely original set of subclasses to a patent with the maximum number of prior patents assigned the same set of subclasses, citations fall off by 62%.
This flavor of result holds up pretty well to a variety of differing methods. For example, Arts and Veugelers (2015) track new combinations in a slightly different way than Fleming, and use a different slice of the data. Rather than counting the number of prior patents assigned the exact same set of technology classifications, they look at the share of pairs of subclasses assigned to a patent that have never been previously combined. This differs a bit from Fleming because they are only interested in patents that are the first to be assigned two disparate technology subclasses, and also because a patent might be a new combination and still be assigned no new pairs. For example, given subclasses A, B, and C, if the pairs AB, BC, and AC have each been combined before, but the set of all three (ABC) has not, then Fleming will code a patent assigned ABC as highly novel and Arts and Veuglers will not.
Arts and Veugelers (2015) look at ~84,000 US biotechnology patents granted between 1976 and 2001 and look at the citations received within the next five years. About 2.2% of patents that forge a new connection between different technology subclasses go on to be one of the most highly cited biomedical patents of all time, compared to just 0.9% of patents that fail to forge new connections. And patents that don’t become these breakthroughs still get more citations if they forge novel links between technology subclasses. Moreover, the direction of this relationship is robust to lots of additional control variables.
As a final example, He and Luo (2017) also establish this result, measuring novel combinations in yet another way, and using an even broader set of data. He and Luo look at ~600,000 US patents granted in the 1990s, and which contain 5 or more citations to other patents. Rather than relying on the technology classifications assigned directly to these patents, they look at the classifications assigned to cited references. They assume a patent combines ideas from the classifications of the patents it cites. They also use a much coarser technology classification system, which has just 630 different technology categories, rather than over 100,000 used in the previous two papers. To measure novel combinations, they look at how frequently a pair of technology classifications are cited together relative to what would be expected by chance. That means they end up with lots of measures of novelty for each patent, one for every possible pair of cited references. To collapse down the set of novelty measures for each patent, they order the pairs of cited reference from the least conventional to most and then grab the median and the 5th percentile.
As a measure of the importance of these patents, we can look at the probability that they are a highly cited patent for the year they were granted and for their technology class. In the figure below, they divide patents up into deciles and compute the probability a patent whose novelty measure falls into that decile is a hit patent. Because they are adapting some earlier work, they set these indices up in a kind of confusing way. In the left figure below, moving from left to right we get increasingly conventional patents, while in the right figure, moving from left to right we get increasingly more unconventional patents.

The figure above shows that when you focus on the most unusual combination of cited technologies made by a patent (the right figure), then more atypical patents have a significantly higher chance of being a hit patent.
When you focus on the median, you find a more complicated relationship: you don’t want all the combinations made to be totally conventional nor totally unconventional and strange. There’s a sweet spot in the middle. Perhaps patents that are completely stuffed with weird combinations are too weird for future inventors to understand and build on?
Addressing some potential problems
The link between unusual combinations of technology classifications and future citations received is pretty reliable across these papers. But before taking these results too far, there are a few potential issues we need to look into.
The first potential issue is a form of selection bias. One challenge from this literature is we typically only ever look at patents that are ultimately granted. But suppose patent examiners are biased against patent applications that make unusual combinations. If that’s the case, then patents making unusual combinations will only make it through if they are so valuable that their merits overcome this deficit. That would, in turn, mean when we are comparing patents that make unusual combinations to other patents, we are comparing a set of elite patents (those good enough to clear the application hurdle) to average patents.
Why would examiners be biased against patents making unusual combinations? This could be the case, for example, if evaluating such a patent requires the examiner to draw on ideas from different disciplines and this is hard to do when the disciplines are particularly unfamiliar and unusual.
Ferguson and Carnabuci (2017) look into this issue using data from the European Patent Office (EPO), which has better data on patent applications that are ultimately not granted, but which otherwise has similar patent application processes as the US Patent and Trademark Office. Before getting into their results on whether new combinations are less likely to be approved, it is worth pointing out that, again, they replicate the same results as the preceding papers: patents at the EPO that make less common combinations tend to receive more citations.
When Ferguson and Carnabuci look at applications, rather than granted patents, they reassuringly find that patent applications that make more unusual combinations are no less likely to be granted. In fact, the opposite is true - highly conventional patents are actually a bit less likely to be approved than unconventional patents! However, this effect is weak enough that when Ferguson and Carnabuci correct for it, the impact on their results is minor. In other words, our first concern is unfounded.
(Ferguson and Carnabuci do find other sources of bias at the patent office though. Patents that draw on more technological disciplines do face a tougher time getting a grant, and this does lead to a spurious inflation of the citations received by patents drawing on many different technological disciplines, since only very good patents overcome this bias. Somewhat surprisingly though, it turns out that drawing on many technological disciplines is relatively uncorrelated with the conventionality of these combinations, which is why we do not detect any significant effect of unconventional combination on the probability of getting approved.)
On to a second possible criticism of this literature. So far, all these papers have looked at the “importance” of a patent by looking at how many citations it receives. We might be interested in a more direct measure of the influence of combinations on the inventive process.
In Clancy (2018) (yes, that’s me), I used yet another technology classification system, this one consisting of the 13,000+ “mainline subclasses” in the US patent classification system, as proxies for the underlying technological “components” of patented innovations. For example, a mainline sub-class might be “Bridge; truss” or “Data processing (artificial intelligence); neural network.” When a patent gets assigned more than one of these, I interpret it as an invention combining these technological components, as in Fleming (2001) or Arts and Veuglers (2014).
Clancy (2018) has a slightly different take on combinatorial innovation than the preceding papers. Instead of just looking at the citations received by a patent making unusual combinations, it tries to get directly at the state of “combinatorial knowledge” so to speak, and see how it influences which patents subsequently get invented. One nice thing about the combinatorial perspective on innovation, is that if you know all the possible technological building blocks you can exhaustively enumerate all possible inventions, including ones that are never actually invented. For example, once components A, B, and C, exist, then the combination ABC is a possible invention, whether or not anyone has actually “done” it. Then you can see what kinds of factors are correlated with possible inventions being realized.
I show a patent with a given combination ABC is more likely to be filed in a year when there are more (prior) patents combining any of the pairs AB, AC, and BC, but less likely to be filed when there are more (prior) patents combining all three (ABC). The following two figures illustrate these dynamics (the different lines correspond to different values for other explanatory variables; i.e., all other variables take the value of the mean, or the mean +/- a standard deviation).

In each figure, we plot the expected annual number of patent applications as we vary the number of times the constituent pairs have been used (above) or the number of times the entire triple-combination has been used (below).

The idea is that inventors learn from the example of successful patents, so anytime they see an invention successfully combining A and B, A and C, or B and C, they have more information about how to combine A, B, and C. Accordingly, it’s more likely such patents will be filed, as in the first figure. On the other hand, patents combining A, B, and C are also instructive, but they also make it harder to patent since it becomes harder to make a novel (patentable) contribution, as in the second figure.
The implication is that innovation enables neighboring ideas that draw on similar but not exactly the same components (another example of how it’s often ideas that are neither too close nor too far that are most useful). It also suggests a reason why so many other papers find patents making unusual combinations receive more citations. In Clancy (2018), new combinations generate valuable knowledge that is used to create similar patents. These are probably more likely to cite their antecedents. Moreover, like Fleming (2001), I find that when a given combination of subclasses becomes more common, patents with the exact same set of subclasses become less likely, which probably attenuates future citations to them. In short, Clancy (2018) suggests citations may well reflect actual new invention that is enabled by unusual combinations of patent.
From Patents to Papers
As mentioned at the outset, we can apply similar ideas to academic papers: do the best new ideas reflect combinations of old ideas here too? Wang, Veugelers, and Stephan (2017) define highly novel papers as those whose citations “combine” journals not previously connected (weighted by how distant the journals are, in terms of the overlap of journals they are usually cited with). They find all sorts of interesting things about papers that make these novel connections. As with Fleming, they find these papers tend to be more highly cited in the long run.

However, they also find evidence of bias against novelty in science: papers making highly novel connections are less likely to appear in high-impact journals, receive a higher share of citations from outside their own field, and citations they do receive take longer to arrive. This suggests there may be some forces of conservatism in science - it would be interesting to know if similar biases show up in the citation data of patents.
Uzzi, Mukherjee, Stringer, and Jones (2013) also looks at papers that make atypical connections between cited journals. Like He and Luo (2017) (which actually adopts their methodology and applies it to patents), they measure the novelty of a combination of journals by the number of times journals have been cited together relative to what would be expected by chance. They also find some ambivalent results about about novelty. The papers most likely to become “hits” (top 5% most highly cited) are those that make a small number of atypical connections but are otherwise highly conventional. Papers that are novel across the board (“low median convention” and “high tail novelty” in the figure below) don’t fare as well.
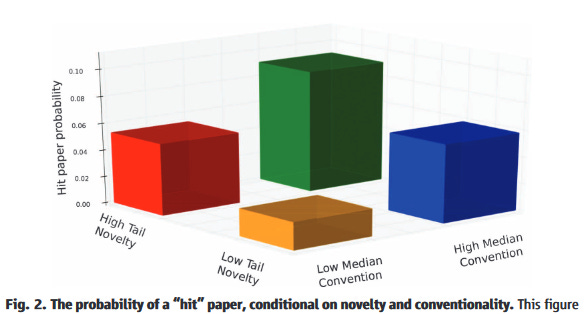
Both these papers find academic papers that make at least some unusual combination receive more citations, consistent with the evidence from patents. Though, again suggesting the possibility of greater conservatism in science, Uzzi and coauthors find for papers it’s good to be highly conventional, whereas He and Luo find an intermediate value of “conventionality” is best for patents (see the first figure in this post, left).
The bottom line though is that a number of papers drawing on different slices of patent data or academic papers find the same thing: innovation that pulls together disparate pre-existing ideas tends to be a particularly useful. The schools of thought that emphasizes combination as the heart of innovation are probably on to something.
New Things Under the Sun is produced in partnership with the Institute for Progress, a Washington, DC-based think tank. You can learn more about their work by visiting their website.